Nos come la IA #14 — La montaña rusa: rey por la mañana, perdido al mediodía
Una mañana del puto amo enseñando a un amigo doce proyectos en paralelo, y unas horas después peleando con la V4 del proceso contable mientras Jaime descubre que su Codex llevaba semana y media en silencio esperando un humano. Por debajo, el muro real de 2026: la memoria de los agentes.
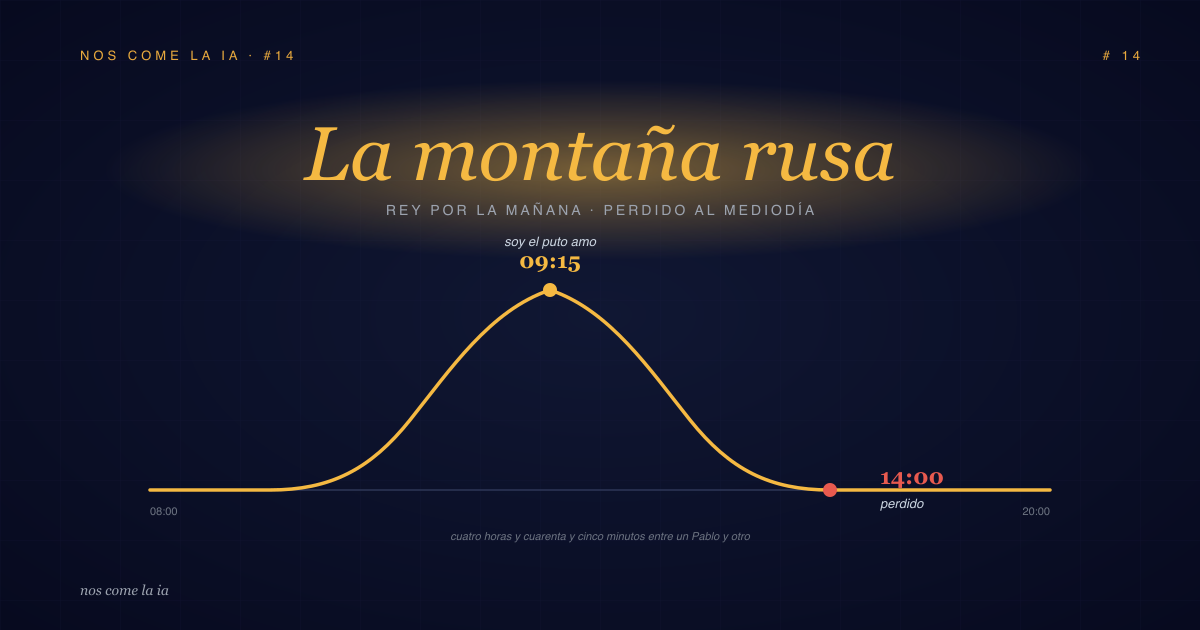
Hay días en los que arranco a las nueve y cuarto, después de dejar a los niños en el cole, y a las dos del mediodía no me reconozco. Empieza uno y acaba otro. Y esta semana lo he tenido muy claro.
Esta misma mañana, sin ir más lejos, le he abierto a un amigo noscomelaia.com/proyectos/ — una página de inventario que monté hace unos días para no tener que explicar uno a uno qué tengo entre manos. Llevo enseñándosela a amigos y a mi mujer toda la semana. Le fui desfilando lo que hay: Intelia, lo único serio de verdad — la plataforma que estamos construyendo para automatizar trabajo administrativo y contable. Mi CRM personal para no perder oportunidades, conversaciones ni contexto comercial. Claucito, mi asistente personal con memoria, WhatsApp y tareas conectadas. Una pequeña web de cuentos infantiles que monté para mis hijos — para descubrir, crear, grabar y escuchar cuentos con ellos. El AI Report diario, que filtra noticias de IA con tesis (no un resumen de titulares, sino las señales que importan). El tracker de despidos atribuidos a IA, semanal. Los dos partidos políticos sintéticos del post de la semana pasada. Los dos SOTA Research nuevos que he colgado esta semana — uno sobre memoria de agentes y otro sobre OCR de facturas con LLMs. Un agente que me preparó las evidencias regulatorias de un Artículo 33 entero. Y la migración del CRM a Postgres self-hosted hecha en una tarde.
La cara de quien mira al otro lado de la pantalla la conozco bien: es la mía de hace un año. Y en ese momento, vale — soy el puto amo. Con la IA siento superpoderes. Cualquier idea que se me ocurre la puedo trasladar a la realidad en minutos u horas. Veo un producto que uso, me cobran cien pavos al mes y digo "esto me lo monto yo en una tarde". Y a veces, ya está dicho, me lo monto. Cosas que hace un año me llevaban tardes enteras las hago en paralelo mientras hago otras dos, supervisando por encima. Tengo un equipo trabajando para mí.
Y hay incluso una restricción rara que, en mi día a día en Intelia, alimenta esa sensación. Por la forma en la que tenemos estructurado el repo principal, no se pueden paralelizar bien dos o tres frentes a la vez ahí dentro; cada cambio o iteración que hago tarda unos 30 minutos en cerrar todo el ciclo de revisión y CI. Así que mientras la IA está trabajando en Intelia, yo me voy a otra cosa — y otra, y otra. Resultado: una página de portfolio que parece justo la barbaridad que es.
Chusmi, comiendo el lunes, me dijo que eso era falta de foco. Puede ser. Para mí son las dos cosas a la vez, y conviven en la misma mañana: por un lado es la hostia — capacidad de tocar mil temas, ver mil ángulos, ser realmente el puto amo de un parque temático mental — y por otro es un drenaje mental a saco. Llegas a la una con la cabeza fundida sin haber acabado nada del todo.
Y luego viene el otro tío. El de las dos de la tarde.
El otro tío: dos meses y medio con la V4
Llevo dos meses y medio peleándome con la misma cosa: automatizar al 100% el proceso contable de gastos de Intelia hacia Holded. Ya voy por la versión 4. Y aquí está la otra cara, sin maquillaje.
La V1 la diseñé de abajo a arriba — conforme me iba haciendo falta contabilizar cosas, iba metiendo casuísticas. Quedó un Frankenstein. Ahí, hasta cierto punto, era yo siendo cabezón. No era problema de la IA.
La V2 es donde me sentí especialmente listo. Diseñé la arquitectura conceptual en un HTML que iba pintándome el modelo conmigo: cajitas conectadas, cada cajita con su input y su output, el flujo entero a vista de pájaro. Jugué con los modelos para que generaran inputs y outputs sintéticos a lo largo del flujo y poder ver cómo se propagaba la información. La hipótesis era preciosa: defino esto a nivel arquitectura conceptual, le monto una batería de casos sintéticos como evals, le pido a la IA que itere hasta que pasen todos, y me lo va a clavar.
Tardó bastante en implementarla. Le di feedback iterando errores por el camino. Y al final, los tests me daban un cómodo 100%. Llegué incluso a montar una herramienta para generarme facturas ficticias y validar end-to-end. Parecía que estaba a un par de pasos de una versión buena.
Y entonces me puse a mirar cómo estaba funcionando por debajo. Todo era ad hoc. Reglas deterministas de texto pegadas con cinta a los casos sintéticos del eval. No generalizaba bien. La arquitectura conceptual que yo había definido en mi HTML no cubría todos los casos reales, y los que no cubría los habían resuelto los LLMs a su manera — saltándose los principios que yo tenía en la cabeza. Resultado: una mierda que yo no podía entender, código que tampoco entendía, y casi una semana y media tirada en algo que parecía funcionar.
Crisis existencial. Empecé a dudar de todo. ¿Es el problema demasiado complejo para mí? No soy desarrollador ni soy contable — no tengo ni el dominio funcional ni el técnico. ¿Estoy siendo impaciente? Igual lo estoy intentando hacer a lo bestia. ¿Es la arquitectura? Quizá no la estoy diseñando bien y por eso no se sostiene cuando aterriza.
Pocos días antes había comido con José María Lucas, co-founder de Tuio, y me había clavado dos frases que me han perseguido toda la semana. La primera, mientras yo le contaba justo este lío: "el problema, Pablo, es que tú no eres contable. Hacer la abstracción de un dominio que no conoces es exactamente lo que te pasa". La segunda, al final de la sobremesa, mientras yo le explicaba lo bonito que era mi framework de cajas evaluables: "¿tú eres el EVAL o eres la caja?". Yo soy la caja final del delivery. Tres meses con la cabeza dentro del rascacielos pensando que estoy construyendo Intelia, cuando lo que estoy haciendo es no operar el negocio. Y lo había avisado un amigo emprendedor el lunes anterior en un café: "te enamoras de la arquitectura, eres más científico que emprendedor". Tres personas, tres ángulos, el dedo en el mismo sitio.
Hablé esa misma noche con Jaime, mi socio. La decisión que hemos tomado es trabajar dos V3 en paralelo, con enfoques opuestos:
- Yo voy a bajar revoluciones. Estoy probando OpenSpec — un framework de spec-driven development que se ha popularizado este trimestre — para consolidar specs en algo validable, no en brainstorms o plans que después se diluyen. Proceso muy paso a paso, sin one-shotear nada. Revisar más cada plan, cada implementación intermedia. Bajar velocidad a cambio de entender.
- Jaime se va por el extremo opuesto. Empezar con un LLM tomando todas las decisiones, un proceso muy no-determinista, y encima un auto-research process que va modificando el prompt para maximizar la exactitud contra un eval training set que tenemos montado. Cuando el LLM satura — cuando no consigue subir más — entonces se le pide a la herramienta que diseñe la parte determinista o que rompa el proceso en fases. Llegar al 100% por la otra orilla.
La lección que va emergiendo de todo este lío, escrita en grande para mí mismo: con la IA, el 80% se hace fácil. El 20% que queda — y sobre todo los últimos puntos hacia el 100% — siguen siendo carísimos. Cada porcentaje extra cuesta más que el anterior. Para procesos donde el scope está claro o donde estás copiando algo que ya existe, ese 80% se siente como magia. Para procesos exploratorios, fuera de tu dominio, con varias fases y un reto conceptual de fondo — la IA ayuda, pero no es el santo grial. Y cruzo los dedos con que esta sea la versión buena.
El efecto gimnasio
Sentado un rato con todo esto, me he dado cuenta de algo importante que conecta el rey de la mañana y el perdido de la tarde. Es como el gimnasio: cuando entrenas un músculo a fondo, el otro pierde vigor.
La IA me hace más creativo, más ambicioso, capaz de paralelizar y cambiar de contexto mucho más rápido. Me obliga a pensar a más alto nivel — la arquitectura, la decisión, el porqué. Mi rol se parece cada vez más al de un CEO-mánager que al de un ejecutor. Eso suena bien. Pero te ahorras músculos que antes tenías: me he vuelto más impaciente, me gusta menos leer las cosas con detalle, delego cada vez más pensamientos por mí mismo. Y hay un momento jodido: si no entiendes lo que está haciendo la IA y no tienes criterio para pararla cuando se va por la calle equivocada, te pierdes con ella. Lo dice el mismo tío que se ha pasado una semana y media descubriendo que su V2 era una colección de parches sin generalización.
Lo que me entrena de vuelta — y por eso lo hago — es escribir este blog. Las entrevistas que me hago a mí mismo cada jueves son básicamente thinking forzado, en el sentido más literal. Lo que sé que debería mejorar y todavía no estoy mejorando es lo siguiente: tengo a alguien trabajando para mí todo el rato, dispuesto a recibir cualquier cosa que le mande. La sensación interna de poder mandar siempre erosiona la sensación de tener que pensar por uno mismo.
Lo que le pasó a Jaime, semana y media seguida
Y por si te suena que esa sensación es solo mía, déjame contarte el episodio paralelo que ilustra el otro extremo del problema, también de esta semana.
Tanto Anthropic como OpenAI han sacado este mes un comando nuevo — /goal — que pone a la IA a trabajar en bucle hasta cumplir un objetivo verificable que tú le has dado. Claude Code 2.1.139 lo lanzó el 12 de mayo; Codex tiene su equivalente. La idea: describes el resultado verificable, no las instrucciones; un modelo validador independiente comprueba si se ha cumplido cada cierto rato; si no, el agente sigue. Para días enteros, si hace falta.
Jaime le puso a Codex el objetivo de rehacer una parte relevante de Intelia. Lo dejó trabajando. Y trabajando. Y trabajando. Día y medio fundiendo todos los tokens semanales de su plan, sin parar. Jaime está en el plan máximo, así que Codex no se le frenaba. Y mientras tanto, Jaime tenía esa sensación tan deliciosa de "estoy ganándole tokens a OpenAI". Un agente top trabajando para él, sin descanso, mientras él hace otras cosas. Pasó una semana. Pasó semana y media.
Y entonces empezó a olerle raro que el avance no se viera por ningún lado. Lo paró. Se metió a mirar qué coño estaba haciendo el agente. No es que se hubiera flipado refactorizando ni que hubiera montado algo grande mal. Resulta que tenía una duda que quería consultarle a un humano y se había quedado esperando indefinidamente. Un bug, puro. Estuvo semana y media — semana y media — pensando que ganaba tokens, cuando en realidad el agente más caro del año estaba parado en silencio esperando un sí que nadie le iba a dar.
La realidad del agente "autónomo" en 2026, dicho rápido: sabe hacer cosas reales — abrirse una cuenta, navegar un dashboard, escribir tests, refactorizar — pero no sabe esperar bien. Parado costaría 0€. En modo "espero pero finjo que no" cuesta semana y media de un plan máximo. Y a Jaime, encima, le cae por su lado el mismo veneno que a mí: la sensación de tener un equipo trabajando que enturbia el reflejo de pararlo y mirar.
Por debajo de toda esta semana: la memoria
Lo que une mi V2 rota y el Codex de Jaime parado no es la velocidad: es el contexto. Qué recuerda el agente, cuándo pregunta y cuándo sabe que se ha perdido. Y ahí es donde llevo trabajando con Jaime hace meses, porque es exactamente lo que va a determinar si todo este teatro de los agentes acaba siendo un producto en serio o un teaser permanente. Se llama memoria. Y es uno de los retos clave que tenemos sobre la mesa en Intelia para 2026.
El razonamiento es bastante directo. Cada vez le queremos delegar más cosas a la IA — tanto en el día a día de desarrollo como en el proceso operativo que ofrecemos al cliente. Para que la IA tome buenas decisiones tiene que tener contexto. Y para que ese contexto sea útil tiene que ser el contexto que necesita para la decisión concreta que está tomando en ese momento. No vale traerle toda la historia del cliente cada vez. Tampoco vale un resumen genérico. El reto está en que cada vez que entra información nueva, el LLM la pula y la guarde de forma ordenada; y en que al recuperarla, los procesos de retrieval acerquen exactamente lo que toca y poco más.
Lo modelamos así. Hay episodios — cualquier interacción con el sistema, una conversación, una factura procesada, un email. De cada episodio salen memorable events: hechos atómicos que merecen quedarse. Y esos memorable events los guardas de varias formas distintas — estructurada, semi-estructurada, episódica — para que al recuperarlos, según para qué tarea, salga la información correcta. Suena ordenado dicho así, en un párrafo. Construirlo bien es donde se rompe uno la cara. Jaime lleva semanas peleando con eso: hemos montado un eval para medir cómo se comportan distintas estrategias de guardado y recuperación, lo cual ya parece más serio que tirar de instinto. Y este lunes colgué un SOTA Research entero sobre el tema — "Memoria de agentes: lo que el campo decidió y lo que nadie resuelve" — que reúne lo que hemos aprendido leyendo a los serios del campo: Mem0, Zep, Letta, Graphiti, Cognee, el Memory Tool de Anthropic, el Memory Bank de Google. Las conclusiones, también hablándolo durante la semana con José María Lucas y con Asís Pardo (su socio en Tuio):
- 2026 va a ser el año de la memoria. O esperamos que lo sea. Lucas y yo, sin acordarlo, dijimos casi la misma frase en la misma comida.
- Hoy nadie llega al 100%. Ni en retrieval — encontrar el documento correcto — ni en decisión — actuar bien con lo encontrado. En los mejores benchmarks públicos el techo está en torno al 80% en la calidad de la decisión.
- La arquitectura es muy dependiente de cada aplicación. Cada proceso tiene que tener su propia estructura de ingestión, guardado y acceso. No hay silver bullet plug-and-play.
- Sí hay patrones que se repiten. Y uno que se nos confirma siempre: cuanto más determinista sea un proceso, más fácil guardar la información de forma estructurada. Cuanto más no determinista, más jodido. Como todo con la IA: siempre que puedas hacer algo determinista, hazlo. Deja lo no determinista para lo que sea genuinamente no determinista.
Estamos probando ahora mismo SuperMemory, una de las capas más interesantes del año pasado. Estamos en tasas en torno al 90%. Y aún así, para el objetivo que necesitamos — no parecer idiotas delante del cliente, que nuestros clientes puedan delegar de verdad en su agente administrativo, y que nosotros podamos delegar de verdad cuando desarrollamos código en Claude o Codex — necesitamos cosas cercanas al 100%. Y todavía no estamos ahí.
Por eso esta semana he leído con otra cara varias cosas que se han movido fuera. La memoria está en lo más alto de la agenda de los gigantes — y eso, viniendo de quien viene, confirma que el problema es real para todos. Tres que merece la pena leer juntas:
Anthropic lanza "Dreaming" en Claude Managed Agents. Un proceso de fondo que, entre sesiones, repasa los logs de interacciones anteriores del agente, identifica patrones, separa lo correcto de lo desfasado y reescribe la memoria externa del agente para mejorar con el tiempo. El modelo subyacente no cambia; lo que cambia es la memoria sobre la que opera. Es exactamente la consolidación asíncrona que el campo llevaba dos años proponiendo en papers — ahora popularizada como producto. Harvey ha reportado un 6× en tasas de finalización de tarea tras implementarlo. Es la confirmación de que vamos por la calle correcta — y de que tampoco ellos dan la memoria por resuelta.
Opus 4.8 y Dynamic Workflows. Anthropic también ha lanzado esta semana Opus 4.8 y un modo nuevo llamado Dynamic Workflows en research preview: Claude planifica trabajo grande, lanza cientos de subagents paralelos dentro de una misma sesión y verifica los outputs. El precio es el mismo que el de Opus 4.7. Simon Willison, en su crónica del lanzamiento, lo describe como "a modest but tangible improvement". No tiene pinta de salto gordo, pero la dirección sí está clara: tareas largas, ejecución paralela, verificación autónoma.
ClickUp despide al 22% y mete 3.000 agentes IA. 290 personas fuera, 3.000 agentes dentro — ratio 3:1 de agentes por empleado. Bandas salariales de un millón de dólares para los que se quedan. El CEO lo llama "100x organisation". Es el ejemplo más visible esta semana del patrón que llevo trackeando hace meses: el mercado paga por la sustitución antes de que la sustitución funcione bien. Y aquí el matiz importa: quien craquee el agente autónomo que codifica de verdad tendrá una valoración brutal — porque reemplaza desarrolladores. Pero reemplaza desarrolladores, no ingenieros. El que tiene ideas, identifica problemas y diseña soluciones sigue en otra capa. Si esto te pilla escribiendo líneas como activo principal, la ventana se está estrechando.
Y dos noticias más, que en realidad apuntan al mismo sitio que todo este post. Catena Labs cierra $30M Serie A y pide charter bancario federal para agentes IA, liderado por Acrew Capital y a16z crypto y fundado por Sean Neville (co-founder de Circle). Está pidiendo a la OCC un charter de National Trust Bank específicamente diseñado para que el titular de la cuenta sea un agente IA: spending limits, allowed payees, audit trail. Hay un movimiento serio para que cosas que hoy hago yo en mi día a día las pueda delegar a un agente con su propia cuenta corriente. Antes incluso de que el agente sepa esperar en silencio, ya va a tener banca propia. Y, como dato final, el Papa: León XIV firmó el 15 de mayo y la Santa Sede publicó el 25 su primera encíclica, Magnifica Humanitas: sobre la salvaguarda de la persona humana en el tiempo de la inteligencia artificial — 42.000 palabras pidiendo "desarmar" la IA, presentada junto a Christopher Olah (co-founder de Anthropic). Hasta el Papa opina ya. Llevamos ahí.
Para cerrar
Esa es la semana, en su pleno aspecto de montaña rusa. El rey por la mañana abriendo noscomelaia.com/proyectos/ con un amigo y haciendo lista de doce cosas; el perdido al mediodía peleando con la V4 mientras Jaime descubre que su Codex llevaba diez días en silencio. Y por debajo, el muro real de 2026 — la memoria — que es lo que va a determinar si todo este teatro de los agentes autónomos acaba siendo un producto en serio o un teaser permanente.
Si tienes la misma montaña rusa esta semana — y por lo que voy hablando con gente, sospecho que somos unos cuantos — me quedo con una regla bastante tonta: cuando me creo Dios, construir pequeño; cuando me siento perdido, no tocar nada hasta entender lo que ya hay. La euforia se aprovecha para acabar algo concreto con scope claro y dominio tuyo, donde la IA solo aporta velocidad. Y el bajón no se cura metiendo más cambios — se cura parando. La velocidad no te salva del rascacielos. El criterio para parar y entender, sí.
Y si trabajas en algo donde la memoria del agente importa más de lo que la industria está reconociendo — bienvenido al club. El año 2026 todavía tiene mucho que mover por aquí.
Nos come la IA es un newsletter semanal de Pablo Muñiz, cofundador de Intelia. Si te ha gustado, compártelo con alguien que esté pasando exactamente la misma montaña rusa esta semana.