Memoria de agentes: lo que el campo decidió y lo que nadie resuelve
9 patrones arquitectónicos convergen en cómo hacer memoria de agente. Ningún vendor cierra el stack: el gap real es decision quality bajo ruido.
Cómo leer esta nota. Está dividida en dos partes. La Parte 1 está pensada para cualquiera con interés en hacia dónde va la IA, sin requisitos técnicos. La Parte 2 entra en la arquitectura, las matemáticas básicas y los papers. Puedes leer una, la otra, o las dos. El TL;DR de abajo aplica a ambas.
TL;DR
- El campo de "memoria para agentes" lleva 18 meses ordenándose. Hoy hay 9 patrones arquitectónicos que casi todos los productos serios comparten — no es consenso explícito, pero es lo que sale cuando ignoras el marketing y miras qué hace cada uno técnicamente.
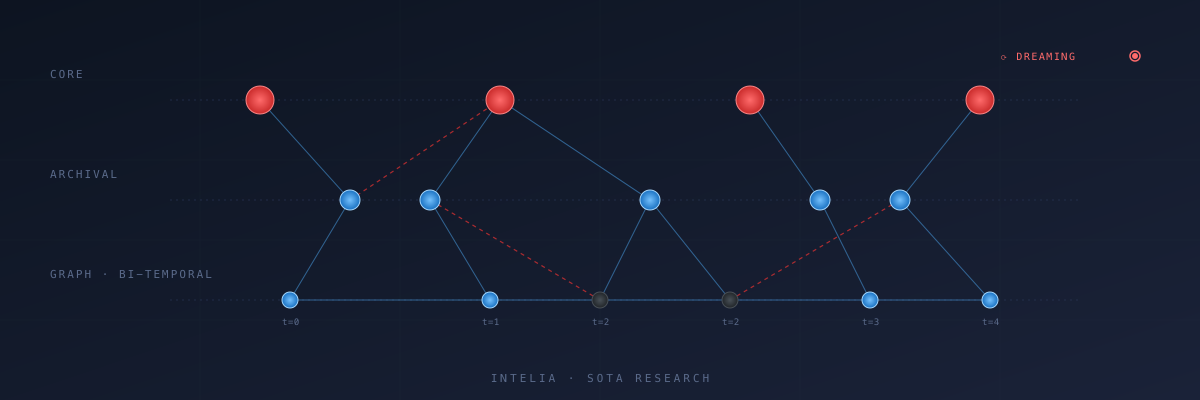
- La arquitectura emergente es: 3 niveles de memoria (working / core curado / archival con grafo bi-temporal) operados por 2 procesos asíncronos (extracción LLM en ingesta + consolidación tipo "dreaming" en background).
- Mem0, Zep, Letta, Graphiti, Cognee, Supermemory, el Memory Tool nativo de Anthropic, el Memory Bank de Google Vertex — todos están convergiendo hacia ese mismo diagrama, viniendo de ángulos distintos.
- El gap que ninguno cierra: medir y mejorar la calidad de la decisión bajo memoria ruidosa. Los benchmarks miden retrieval (¿subió el documento correcto al top-k?), no decisión (¿el agente tomó la decisión correcta?). El techo del ~80% de accuracy que vemos en todos los benchmarks viene de ahí.
- Implicación práctica: usar el diagrama de referencia para evaluar vendors y construir tu eval privada de decision quality. No existe todavía el producto "memoria perfecta plug-and-play" — quien lo venda, miente.
Parte 1 — Para entender de qué va, sin tecnicismos
El problema
Imagínate un becario que lleva seis meses con un cliente. En teoría lo sabe todo: las facturas, el contable, las preferencias, las discusiones del trimestre pasado. Llega la reunión y, con toda la confianza del mundo, cita una factura mal contada en febrero, recuerda una preferencia del cliente que dejó de ser cierta en marzo, y trae a colación un email viejo que el cliente ya considera zanjado. El cliente se enfada. ¿El becario es malo? No. El problema es que su memoria mezcla cosas, no distingue qué sigue vigente y qué no, y trae al presente recuerdos irrelevantes con la misma seguridad que los relevantes.
La memoria de un agente IA tiene exactamente el mismo problema, pero con números encima: en la mejor configuración pública disponible hoy, un agente IA con memoria persistente acierta el "documento correcto" un 80-90% de las veces, pero toma la decisión correcta solo un ~80%. El gap entre esos dos números —entre encontrar la información y usarla bien— es donde vive el problema real. No es un problema de algoritmo de búsqueda. Es un problema de qué entra en la memoria, qué se cura, qué se olvida y qué se invalida cuando deja de ser cierto.
Llevamos tres años hablando de "memoria de agente" como si fuera un componente que se compra o se enchufa. La realidad es que, a mayo de 2026, ni los productos comerciales más serios (Mem0, Zep, Letta, Supermemory) ni los proyectos open source más prometedores (Graphiti, Cognee, Memori) resuelven el problema completo. Pero — y esto es lo interesante de este artículo — sí que han convergido, sin ponerse de acuerdo, en cómo debería ser la arquitectura. Esto es lo que vamos a contar.
Por qué importa esto para tu negocio
Memoria de agente parece un debate técnico para ingenieros, pero es exactamente lo que separa un piloto vistoso de un sistema que entrega valor real. Tres ejemplos concretos:
- Caso 1: asistente que escribe el email semanal al cliente. Tienes un humano que cada semana recopila qué ha pasado con un cliente (facturas, llamadas, emails, decisiones) y manda un resumen accionable. Si el agente que lo automatiza no recuerda con precisión qué se decidió hace tres semanas, qué quedó pendiente y cuál es la preferencia de comunicación del cliente, lo que produce es ruido — y mancha la relación.
- Caso 2: agente contable que aprueba o cuestiona. Un agente que decide si una factura encaja con el patrón histórico de un proveedor necesita memoria correcta sobre ese proveedor: cómo facturó los últimos seis meses, qué excepciones hubo, qué dijo el cliente sobre él. Una memoria ruidosa hace que el agente cuestione lo correcto y apruebe lo dudoso.
- Caso 3: CRM o sales agent que recomienda la siguiente acción. Si la memoria mezcla intereses antiguos del cliente con los actuales, las recomendaciones son irrelevantes. El equipo deja de fiarse. El sistema muere.
En los tres casos el bottleneck no es la inteligencia del LLM (Claude Opus 4.7, GPT-5.1 o Gemini 2.5 son más que suficientes para razonar) ni la cantidad de información (caben millones de tokens en contexto). El bottleneck es qué pones en el contexto y por qué. Y eso es exactamente el problema de la memoria.
Las apuestas: quién está construyendo qué
El espacio se ha llenado de productos desde 2024. Si quitas el marketing y te quedas con los serios, hay tres ángulos de ataque distintos:
- Memoria como capa SaaS gestionada. Tú llamas a una API, ellos guardan, ellos extraen, ellos recuperan. Mem0, Supermemory, Zep Cloud, Letta Cloud. Más rápido de adoptar, vendor lock-in alto.
- Memoria como motor open source que tú self-hosteas. Graphiti, Cognee, Memori, Letta self-host, LangMem. Más trabajo de operar, libertad total.
- Memoria nativa al proveedor LLM. Anthropic Memory Tool + Dreaming, Google Vertex Memory Bank, ChatGPT Memory. Cero servicio extra, lock-in completo al modelo.
Y entre los tres, hay una diferencia filosófica que está empezando a separar ganadores de perdedores: memoria legible vs memoria opaca. La memoria que un humano puede leer, editar y borrar (filesystem, markdown, SQL) está ganando terreno frente a la memoria como blob de embeddings en una base de datos vectorial.
Hacia dónde va esto
Mi lectura del rumbo a 12 meses, a partir de lo que cada player está construyendo y de los anuncios de los grandes laboratorios:
- El stack ganador va a ser híbrido, no un solo producto. Una capa de memoria curada por humano (legible, editable), una capa de hechos extraídos por LLM (vector + grafo), y un proceso asíncrono que consolida y limpia entre sesiones. Nadie va a ganar "vendiendo memoria" — la memoria va a ser un componente.
- La consolidación asíncrona deja de ser feature exótica. Letta lo llevaba años defendiendo. Anthropic acaba de popularizarlo con Dreaming (mayo 2026). En 12 meses, cualquier sistema serio va a tener un "proceso que duerme y reescribe la memoria" entre sesiones.
- Memoria como vector de ataque ya tiene categoría regulada. OWASP añadió ASI06 — Memory & Context Poisoning — al Top 10 for Agentic Applications 2026. Cualquier RFP enterprise va a pedir narrativa de seguridad de la memoria. Vendors sin audit trail ni capacidad de borrar "memorias envenenadas" van a quedarse fuera.
- El problema duro sigue siendo "decision quality bajo memoria ruidosa". Y ahí no hay producto comercial que tenga respuesta. Quien resuelva esto —probablemente combinando reflection + curación humana + métricas de decisión, no solo de retrieval— construye la próxima Mem0.
Para un decisor: no compres "memoria" como producto cerrado todavía. Construye el diagrama híbrido (te lo dejamos en la Parte 2), mide decisión, no retrieval, y elige vendors que cumplan piezas concretas del diagrama, no "todo".
Si quieres entender cómo funciona cada una de estas líneas y por qué algunas son más prometedoras que otras, sigue a la Parte 2.
A partir de aquí, la Parte 2 entra en arquitectura, matemáticas y papers. Si solo te interesaba el "qué" y no el "cómo", puedes parar aquí.
Parte 2 — Cómo funciona por dentro (técnica)
2.1 — Fundamentos
La taxonomía canónica de memoria en agentes viene del paper CoALA — Cognitive Architectures for Language Agents (Sumers, Yao, Narasimhan, Griffiths, arXiv:2309.02427, sometido sept 2023, versión final marzo 2024). CoALA hereda de la psicología cognitiva clásica cuatro tipos:
- Working memory — contenido del prompt activo en la sesión actual. Es lo que el LLM tiene "delante" mientras razona.
- Episodic memory — eventos específicos con timestamp. "El martes pasado el cliente X dijo Y por email a las 11:34".
- Semantic memory — hechos abstraídos atemporales. "El cliente X prefiere PDF y paga a 60 días".
- Procedural memory — workflows aprendidos. "Cuando este cliente envía factura, hay que validar el IBAN contra la última recibida".
MemGPT (Packer, Wooders, Lin, Fang, Patil, Stoica, Gonzalez, arXiv:2310.08560, 2023) introdujo la metáfora "LLM como sistema operativo": memoria jerárquica con main context (equivalente a RAM, lo que cabe en el prompt) y external context (equivalente a disco, accedido vía tools de búsqueda). El propio LLM decide qué paginar entre niveles. Esta metáfora — paging entre niveles, función tools como interrupciones — sigue estructurando el debate tres años después.
Una revisión actualizada útil es Memory for Autonomous LLM Agents: Mechanisms, Evaluation, and Emerging Frontiers (Du, arXiv:2603.07670, marzo 2026). Formaliza el ciclo de vida de la memoria como write → manage → read:
┌─────────────┐
evento → │ WRITE │ (extracción, embedding)
└──────┬──────┘
▼
┌─────────────┐
│ MANAGE │ (consolidación, invalidación,
└──────┬──────┘ forgetting)
▼
query → ┌─────────────┐
│ READ │ → contexto LLM
└─────────────┘Todo lo que sigue es alguna combinación específica de qué pasa en write (cómo extraer hechos), qué pasa en manage (cómo consolidar, olvidar, invalidar) y qué pasa en read (cómo decidir qué recuperar). Las diferencias entre Mem0, Zep, Letta, Cognee y Anthropic Memory Tool son fundamentalmente diferencias en esas tres etapas.
2.2 — Las líneas de research / approaches arquitectónicos
A) Long-context puro
Tira más contexto, olvida la memoria. Llama 4 Scout (10M tokens), Gemini 2.5 Pro (1M-2M), Claude Opus 4.7 (200K-1M extended). Para conversaciones largas y documentos densos puede ser suficiente. Falla por dos vectores conocidos:
- Lost-in-the-middle (Liu et al., arXiv:2307.03172, 2023): la accuracy de retrieval cae cuando el dato relevante está en el medio del contexto largo. Los modelos atienden mejor a principio y final.
- Coste y latencia: lineal/cuadrático en tokens. 1M tokens por request a precios de Opus 4.7 son inviables como patrón normal.
Estado: producción para casos puntuales (documento largo, sesión de horas). Insuficiente cuando la relación con un cliente dura años y no puedes meter 5 años de emails en cada llamada.
B) Vector DB + RAG clásico
Stack canónico inaugurado por RAG — Retrieval-Augmented Generation (Lewis et al., NeurIPS 2020, arXiv:2005.11401). Embed chunks, indexa, recupera top-k por similitud coseno, mete en el prompt. Evolución importante: Self-RAG (Asai, Wu, Wang, Sil, Hajishirzi, ICLR 2024, arXiv:2310.11511) — el modelo aprende cuándo recuperar y critica su propia generación mediante reflection tokens.
Pros: maduro, barato, escalable. Cualquier vector DB (Pinecone, Qdrant, pgvector) lo soporta.
Contras: el chunking pierde estructura semántica. Pobre en temporal ("¿qué dijo el cliente la última vez?") y multi-hop ("¿qué cambió entre la decisión X y la decisión Y?"). Tratar toda la memoria como una sola colección de embeddings es la causa raíz del "ruido en asociaciones" que mata decisión.
Estado: producción universal, pero crecientemente insuficiente como capa única.
C) Jerárquica tipo sistema operativo
MemGPT (ya citado) materializado en Letta (letta.com). Tres niveles:
core_memory— siempre pinned al prompt, bloques editables (persona,human, custom). Equivale a RAM.recall_memory— historial conversacional completo, queryable.archival_memory— vector store externo de hechos explícitos. Equivale a disco.
El agente mismo gestiona el paging vía tools (core_memory_append, archival_memory_insert, conversation_search). Estado serializado en Postgres/SQLite. Letta promueve además MemFS (memoria como filesystem git-tracked) y sleep-time compute (consolidación en background).
Caso de producción documentado: Bilt Rewards corre >1M de agentes Letta en producción para recomendaciones de comercio local. Es la mejor evidencia pública de que el patrón "agente stateful con identidad por usuario" escala.
Trade-off: más caro en tokens por single-shot recall (varios tool calls) a cambio de control fino y debugging visual (el ADE de Letta es el único producto del espacio con UI seria para inspeccionar memory blocks).
D) Knowledge graph bi-temporal
Zep — A Temporal Knowledge Graph Architecture for Agent Memory (Rasmussen, Paliychuk, Beauvais, Ryan, Chalef, arXiv:2501.13956, enero 2025). Motor open source: Graphiti (github.com/getzep/graphiti, 26.5k stars).
Cada hecho es una arista con valid_from y valid_to. Cuando llega un hecho nuevo que contradice uno antiguo, no se sobrescribe: el anterior se marca como invalidado con timestamp. El grafo conserva la historia completa de qué se creía en cada momento. Permite queries tipo "¿cuál era la dirección de facturación del cliente en marzo vs ahora?".
Resultados reportados (paper): 94.8% en DMR (vs 93.4% MemGPT), +18.5% sobre baseline en LongMemEval con 90% menos latencia.
Caveats fuertes:
- Cada
add_episodedispara extracción LLM + dedupe contra el grafo entero → coste por escritura desproporcionado para alta frecuencia. Benchmark independiente (dev.to/juandastic) mide Graphiti consumiendo 1.68×-2.25× más tokens que Mem0. - Neo4j operacionalmente pesado en stacks que no lo tienen ya (RAM agresiva, Cypher, backup propio).
- Zep deprecó Community Edition en abril 2025 (anuncio). Self-host serio = montar tú Graphiti + tu propia orquestación.
Cuándo merece la pena: cuando los hechos cambian con el tiempo y necesitas razonar sobre versiones anteriores (compliance, auditoría, contexto histórico de cliente). Cuando NO: ingesta de alta frecuencia con presupuesto LLM ajustado.
E) Agentic / self-organizing memory
A-MEM — Agentic Memory for LLM Agents (Xu, Liang, Mei, Gao, Tan, Zhang, arXiv:2502.12110, NeurIPS 2025). Inspirado en Zettelkasten: cada memoria es una nota atómica con descripción, keywords y tags. Cuando llega una nueva, el LLM la enlaza con notas existentes y actualiza notas previas si el nuevo contenido las modifica. Es un knowledge graph construido por LLM en vez de por reglas.
Mem0 (Chhikara, Khant, Aryan, Singh, Yadav, arXiv:2504.19413, ECAI 2025). Servicio gestionado de extracción/consolidación de hechos. Variante grafo (Mem0g) en tier Pro. La v3.0 (abril 2026) introdujo Single-pass ADD-only extraction — elimina el caro paso UPDATE que era el cuello de botella histórico.
Resultados reportados por Mem0 v3 en mayo 2026: LoCoMo 92.5%, LongMemEval 94.4%, BEAM-1M 64.1%. Pero Zep desmontó públicamente el paper original de Mem0 (Lies, Damn Lies, Statistics, mayo 2025) por errores de implementación al evaluar competidores. Tomarlos con escepticismo.
Estado: A-MEM = research, no producción. Mem0 = el más maduro como SaaS plug-and-play.
F) Episodic event-based
EM-LLM — Human-inspired Episodic Memory for Infinite Context LLMs (Fountas et al., arXiv:2407.09450, sometido jul 2024, aceptado ICLR 2025). Segmenta secuencias de tokens en "eventos episódicos" usando Bayesian surprise: cuando el modelo se sorprende ante un nuevo token (la probabilidad asignada es muy baja), marca el límite de un evento. Refinamiento posterior con métricas grafo-teóricas. El retrieval combina similitud semántica con contigüidad temporal.
Supera modelos full-context en LongBench/∞-Bench y maneja secuencias de 10M tokens.
Estado: muy interesante académicamente pero requiere acceso a internals del modelo (attention weights, logits). Inútil si usas APIs cerradas como Claude/GPT.
G) Memory consolidation / reflection
Patrón, no producto. Aparece en varios sitios.
Reflexion (Shinn, Cassano, Berman, Gopinath, Narasimhan, Yao, NeurIPS 2023, arXiv:2303.11366) — tras cada trial el agente "verbalmente" reflexiona y guarda el aprendizaje en memoria episódica para mejorar en intentos posteriores.
Generative Agents (Park, O'Brien, Cai, Morris, Liang, Bernstein, arXiv:2304.03442, 2023) — los famosos agentes de Stanford en Smallville. Introdujeron tres componentes que han marcado el campo: memory stream (registro de eventos), reflection (síntesis periódica de memorias en abstracciones de mayor nivel) y planning (uso de las anteriores para decidir qué hacer). Sin reflection los agentes colapsan en 48h simuladas — el paper lo prueba.
En 2025-2026 este patrón se ha vuelto mainstream:
- Letta sleep-time compute — procesos en background que consolidan memoria entre sesiones.
- Anthropic Dreaming (mayo 2026) — proceso programado que relee hasta 100 sesiones pasadas y reescribe el memory store: dedup, refresh, surfacing de patrones. Harvey reportó +6× en task-completion rate tras activarlo en drafting legal.
- Cognee — paso "Cognify" en el pipeline ECL hace exactamente esto en background.
H) Procedural memory / skill learning
Voyager (Wang, Xie, Jiang, Mandlekar, Xiao, Zhu, Fan, Anandkumar, arXiv:2305.16291, 2023) en Minecraft. El agente acumula una biblioteca de skills ejecutables (código) y los reusa. Cuando aparece una situación nueva, busca skills existentes antes de generar código nuevo.
MemoryBank (Zhong et al., arXiv:2305.10250, 2023) incorpora la curva del olvido de Ebbinghaus como heurística de forgetting: las memorias decaen exponencialmente salvo que se refuercen por uso.
Estado: el paradigma de "skill library aprendida" funciona mejor en entornos con código ejecutable (coding agents) que en back-office. Pero el patrón "memoria procedural = el agente reescribe su propio system prompt" ha entrado en producción vía LangMem (LangChain) y vía custom prompts versionados en repositorios.
2.3 — Los 9 consensos del campo
Si quitas el marketing y miras qué hace cada producto técnicamente, 9 patrones se repiten en casi todos los players serios. Esta es la respuesta tácita del campo a "cómo se hace memoria de agente que funciona".
1. La memoria es híbrida (vector + grafo), no una sola estructura
Mem0g añadió grafo en 2025. Zep/Graphiti es grafo-first pero con vector debajo. Cognee construye los dos en paralelo desde su pipeline ECL. Supermemory tiene "vector-graph engine con ontology-aware edges". Incluso Memori (SQL-native) implementa el grafo como tablas relacionales.
Por qué importa: vector para similitud difusa ("encuentra algo parecido a esto"), grafo para relaciones tipadas y razonamiento multi-hop ("¿qué proveedores comparten contacto con este cliente?"). Quien venda "solo vector" en 2026 H2 vende 2023.
2. La extracción de hechos la hace el LLM, no reglas
Mem0 lo hace ADD-only en v3. Letta lo deja al agente vía tools. Cognee lo hace en el paso Cognify. Graphiti lo hace en cada add_episode. Supermemory en el background del router.
Por qué importa: la NLP clásica (NER + relation extraction + reglas) está muerta para este caso. El coste de extracción LLM es la unidad económica de la memoria — todo el debate de pricing gira alrededor de cuántos tokens consume cada write. Mem0 v3 redujo este coste a la mitad eliminando el paso UPDATE.
3. Niveles cognitivos separados (factual / reflective / profile / procedural)
CoALA propuso la taxonomía en 2024. Tres años después, cada producto serio acaba implementándola de algún modo:
- Letta:
core_memory(procedural + profile),recall_memory(episodic),archival_memory(semantic/factual). - LangMem: explícitamente
semantic / episodic / proceduralcomo categorías. - MemBench, MemMachine: distinguen factual / reflective / profile como categorías de evaluación.
- Anthropic Memory Tool: filesystem que el desarrollador estructura por tipo.
- Mem0: hechos atómicos + grafo de preferencias.
Por qué importa: tratar toda la memoria como una sola tabla de embeddings es la causa raíz del "ruido en asociaciones". Si no separas niveles, los hechos episódicos contaminan las decisiones semánticas y viceversa.
4. Hot path ligero, consolidación pesada en background
ReMe (ex-MemoryScope) lo explicita: operaciones backend separadas del path de respuesta, ~500ms. Letta lo institucionaliza con sleep-time compute. Anthropic Dreaming (mayo 2026) lo lleva al mainstream: proceso programado que relee sesiones pasadas y reescribe memoria. Cognee separa Extract / Cognify (background) de Load / Search (hot). Generative Agents (Park 2023) introdujo reflection periódica como requisito.
Por qué importa: lo que pasa entre sesiones importa tanto como lo que pasa en sesión. Memoria que solo se escribe-en-caliente y se lee-en-caliente colapsa en semanas. La consolidación asíncrona ya no es feature avanzada — es requisito.
5. Razonamiento temporal de primera clase (bi-temporal)
Graphiti lo definió: cada hecho tiene valid_from/valid_to, los hechos no se sobrescriben, se invalidan. Cognee lo trae en su pipeline. Anthropic Dreaming reescribe memoria con awareness de qué cambió. ChatGPT memory destila resúmenes con orden temporal. Mem0 está añadiendo timestamps como first-class.
Por qué importa: la memoria sin tiempo es mentira. El cliente cambió de método de pago en marzo. El proveedor cambió de IBAN en abril. El contable se mudó en mayo. Memoria que no sabe cuándo dejó de ser cierto algo es memoria que da respuestas obsoletas con confianza.
6. La memoria debe ser legible por humanos
Anthropic Memory Tool = filesystem dedicado, markdown/JSON. Letta MemFS = git-tracked. ByteRover = "todo markdown legible, zero infra". Memori = SQL puro. ReMeLight = ficheros markdown/JSONL local.
Andrej Karpathy ha sido uno de los promotores públicos más visibles de esta tesis: la memoria del agente debería vivir como markdown/wiki legible que un humano pueda leer y editar, no como vector opaco en una base de datos. La dirección está ganando — pero, como veremos, el wiki legible es necesario, no suficiente: resuelve quién puede inspeccionar la memoria, no resuelve qué entra al wiki, qué se considera vigente y qué decisión toma el agente con lo que recuerda. Es exactamente la trampa en la que cae cualquiera que prueba un "MDWiki estilo Karpathy" como capa única y descubre que el problema de decisión bajo memoria ruidosa sigue ahí.
Crítica común al RAG vectorial puro: no puedes leer ni editar lo que el agente cree saber sobre ti. Si la memoria es un blob de 1536 dimensiones en Pinecone, ningún humano puede inspeccionarla.
Por qué importa: un humano tiene que poder leer, borrar y editar lo que el agente recuerda. La narrativa de 2026: memoria como sistema de archivos versionable, no como base de datos black-box. Esto tiene además implicaciones de safety (ver consenso 9).
7. La memoria es propiedad del proceso, no global
Letta: una memoria por agente. Mem0: filtrado por user_id. Supermemory: container_tag. Cognee: tenant + audit trail. La propia Intelia formuló esto internamente como "process-driven memory: cada proceso declara qué quiere recordar y cómo".
Por qué importa: no existe "la memoria del agente" universal. Existe la memoria de este caso de uso, sobre esta entidad, con este propósito. Productos que intentan ser "memoria universal cross-LLM cross-app" (varias extensiones Chrome, plurality.network) están fracasando porque ignoran este consenso.
8. Curación humana en el loop, no fully autonomous
Anthropic Memory Tool: el desarrollador define schema y endpoints. Letta core_memory: editable manualmente vía ADE. Cognee: audit trail con provenance por página (caso University of Wyoming). Memori: SQL → cualquier humano hace UPDATE.
Por qué importa: la memoria 100% autónoma del agente no funciona en producción porque introduce errores que escalan multiplicativamente. El patrón ganador es humano cura el "core", agente cura el "archivo". Quien venda "set it and forget it" sin curación es quien acaba con drift envenenado.
9. Memory safety como categoría reconocida
OWASP ASI06 — Memory & Context Poisoning se añadió al Top 10 for Agentic Applications (publicado dic 2025) como categoría reconocida de riesgo en agentes. La literatura académica de 2025-2026 ya documenta vectores concretos: Remembering More, Risking More (arXiv:2605.17830, may 2026) sobre el riesgo creciente con memoria persistente, y Persistent Compromise of LLM Agents via Poisoned Experience Retrieval (arXiv:2512.16962, dic 2025) que muestra cómo envenenar la memoria episódica de un agente para comprometerlo a largo plazo.
Por qué importa: la memoria persistente es vector de ataque y el campo ya lo reconoce. Cualquier RFP enterprise de 2026 H2 va a pedir narrativa de safety. Vendors sin audit trail, sin provenance, sin capacidad de borrar selectivamente memorias envenenadas están en problemas.
2.4 — La arquitectura de referencia emergente
Si dibujas el agente con memoria de mayo 2026 que cumple los 9 consensos, sale algo así:
┌──────────────────────────────┐
│ HUMANO (curador del core) │
└─────────────┬────────────────┘
│ edita / aprueba
▼
┌────────────────────────────────────────────────────────────────┐
│ AGENTE (hot path, <1s) │
│ ┌─────────────────┐ ┌──────────────┐ ┌────────────────┐ │
│ │ working mem │ │ core memory │ │ retrieval híbr │ │
│ │ (contexto LLM) │ ← │ (legible, │ ← │ vector + BM25 │ │
│ │ │ │ curado) │ │ + grafo trav. │ │
│ └─────────────────┘ └──────────────┘ └────────────────┘ │
│ ▲ │
└──────────────────────────────────────────────────│─────────────┘
│
┌────────────────────────────────────┴──┐
│ STORAGE (memoria persistente) │
│ ┌─────────────┐ ┌──────────────┐ │
│ │ archival │ │ knowledge │ │
│ │ (vector + │ │ graph │ │
│ │ markdown) │ │ (bi-temporal)│ │
│ └──────┬──────┘ └──────┬───────┘ │
└─────────│────────────────│────────────┘
▲ ▲
│ │
┌───────────────┴────────────────┴───────────────┐
│ BACKGROUND / SLEEP-TIME (cron, dreaming) │
│ │
│ • extracción LLM de eventos → triples │
│ • consolidación (dedup, resolución contradic) │
│ • reflection (síntesis de patrones N días) │
│ • invalidación temporal de hechos obsoletos │
│ • audit trail + provenance │
└────────────────────────────────────────────────┘
▲
│
┌───────────────┴────────────────┐
│ FUENTES (eventos brutos) │
│ email, llamadas, docs, CRM, │
│ chat, transacciones, etc. │
└────────────────────────────────┘Las piezas y quién las representa mejor hoy:
| Capa | Función | Quién la encarna mejor |
|---|---|---|
| Working memory | Contexto activo del LLM | Cualquier LLM con contexto largo (Claude 1M, Gemini 2M) |
| Core memory legible | Hechos curados, editables por humano | Anthropic Memory Tool, Letta core_memory, MemFS |
| Retrieval híbrido | Vector + BM25 + grafo en una query | ReMe, Supermemory, Zep |
| Archival (vector + md) | Historial completo, queryable | Mem0, Letta archival, Cognee |
| Knowledge graph bi-temporal | Hechos con validez temporal | Graphiti, Cognee |
| Sleep-time / Dreaming | Consolidación asíncrona | Letta sleep-time, Anthropic Dreaming, Cognee Cognify |
| Extracción LLM | Eventos brutos → triples | Mem0, Graphiti, Cognee — todos usan LLM |
| Audit / provenance | Por qué algo está en memoria | Cognee, Memori |
Lo que NO está en este diagrama y debería:
- Forgetting policy aprendida. Todos los productos usan heurísticas (Ebbinghaus en MemoryBank) o TTL fijos (Mem0 default). No hay aprendizaje real de qué olvidar.
- Cross-session identity resolution. El mismo cliente vía email, WhatsApp, web, móvil — sin resolver fuera del enterprise SSO clásico.
- Decision-quality scoring. Medir si la memoria recuperada realmente mejoró la decisión final, no solo si fue relevante a la query. Este es el gap del 80% de decision accuracy que vemos en todos los benchmarks.
2.5 — Benchmarks: por qué no fiarse
Los tres benchmarks de referencia miden cosas distintas y los players se auto-evalúan.
- LoCoMo — Evaluating Very Long-Term Conversational Memory (Maharana et al., arXiv:2402.17753, 2024). Diálogos hasta 35 sesiones / ~9k tokens cada uno. QA single/multi-hop, temporal, open-domain.
- LongMemEval (Wu et al., ICLR 2025, arXiv:2410.10813). El benchmark de referencia 2026. 500 preguntas evaluando 5 capacidades: extracción, multi-session reasoning, temporal reasoning, knowledge updates, abstención. Settings 115k y 1.5M tokens.
- BEAM — Beyond a Million Tokens (arXiv:2510.27246, oct 2025). 2000 preguntas hasta 10M tokens. Tareas nuevas: contradiction resolution, event ordering, instruction following.
Casos concretos donde el discurso público se rompió:
- Mem0 reportó 92.5% en LoCoMo. Zep recalculó 75.14% ± 0.17 corrigiendo errores de implementación (searches secuenciales donde Zep necesita paralelos).
- Crítica de Zep: LoCoMo cabe entero en context window moderno; baseline full-context da ~73% sin sistema de memoria. Si tu benchmark se gana metiendo todo al prompt, no mide memoria.
- En Q1 2026 salieron benchmarks alternativos: MemoryAgentBench (4 competencias cognitivas), MemBench (factual vs reflective), MemoryArena (multi-session interdependiente), AMA-Bench (long-horizon). El campo pasó de 1 benchmark a 4-5 en un trimestre — señal de inmadurez.
Conclusión: el único benchmark que cuenta es el privado, con datos reales del caso de uso. Cualquier blog de vendor que cite SOTA sin reproducir el setup independiente vale cero.
2.6 — Tres debates abiertos en 2026 Q2
Long context vs memory layer. Llama 4 Scout con 10M tokens, Gemini 2.5 Pro con 2M, Claude Opus 4.7 con 1M extended. ¿Mata esto la necesidad de capa de memoria externa? Consenso emergente (Karpathy + Lütke popularizando el término): no, lo que muere es el discurso de "memoria como producto aislado". Lo que reemplaza es context engineering como disciplina paraguas, donde la memoria es un componente del contexto, no su sustituto.
Filesystem-as-memory vs blob-opaco-en-vector-DB. Anthropic Memory Tool, ByteRover, Letta MemFS y Memori convergen en "memoria como markdown/SQL legible, versionable, auditable" en vez de "embedding en Pinecone". Crítica al RAG vectorial puro que se ha vuelto mainstream: un agente no debería tener memoria que un humano no pueda leer ni editar.
¿El agente cura su memoria o el desarrollador define el schema? Letta apuesta por "agente se auto-edita memoria con tools". Anthropic Memory Tool apuesta por "tú das el schema, el agente lo rellena". Ambas tienen tracción, conviven. Probablemente acabe siendo "depende del caso de uso", pero por ahora es debate vivo.
2.7 — Mi lectura del estado del arte
Tabla comparativa de approaches:
| Approach | Madurez | Probabilidad de impacto | Riesgo |
|---|---|---|---|
| Long-context puro | Alta | Media | Bajo (cara, pero funciona) |
| Vector RAG | Muy alta | Baja como capa única | Bajo |
| MemGPT / Letta | Media | Alta | Medio (latencia, depende del LLM) |
| Zep / Graphiti | Media | Alta para compliance | Alto (vendor 5 pers, OSS deprecado) |
| A-MEM / Mem0 | Media-alta | Media | Medio (benchmarks discutidos) |
| EM-LLM | Baja | Solo si controlas el modelo | Alto |
| Reflection (Park/Shinn) | Patrón, no producto | Alta | Bajo |
| Voyager-style skills | Baja en back-office | Media | Medio |
Mi tesis: el campo está convergiendo en una arquitectura híbrida de 3 niveles (working / core curado / archival con grafo bi-temporal) operada por dos procesos asíncronos (extracción LLM en ingesta + consolidación tipo Dreaming en background). Lo que aún no funciona y por lo que ningún producto comercial resuelve el stack completo es: medir y mejorar la calidad de decisión bajo memoria ruidosa. Los benchmarks miden retrieval. La decisión es otro problema. Y por eso quien meta 4 productos comerciales en producción acaba con el mismo techo del ~80% de decision quality, que es exactamente lo que estamos viendo en pruebas internas.
Quién está mejor posicionado para los próximos 12 meses:
- Anthropic si Dreaming sale de gated beta → mata buena parte del value-prop de Mem0/Zep/Supermemory para clientes ya en Claude.
- Cognee como vendor independiente serio con datos enterprise reales (Bayer, dltHub, University of Wyoming) y backing de OpenAI alumni ($7.5M seed feb 2026).
- Letta si el patrón "agente con identidad persistente" se consolida como UX (probable, dado que es lo que ya hacen ChatGPT Memory + Claude Projects).
- Apostaría menos por Zep dado que cerraron OSS y tienen runway de 5 personas con $500K. Y por Supermemory dado el riesgo bus factor (fundador veinteañero, equipo <10), aunque el producto es serio.
2.8 — Implicaciones prácticas
Para alguien que tome decisiones técnicas sobre memoria de agentes hoy:
- Mapea tu stack actual contra los 9 consensos. Si te falta uno (especialmente bi-temporal, sleep-time consolidation o curación humana), eso es probablemente donde está tu techo de decision quality.
- No compres vendor como "memoria todo-en-uno" todavía. Selecciona piezas concretas del diagrama de referencia. Letta para core stateful + Cognee para grafo + Anthropic Memory Tool para working son combinaciones razonables; Mem0 monolítico es atajo, no solución.
- Construye tu eval privada antes que cualquier benchmark público. Tomas 50-100 casos reales de tu dominio. Métrica: ¿el agente con memoria toma la misma decisión que el humano experto? Si no, ¿por qué? (memoria errónea, memoria irrelevante, memoria correcta pero mal usada).
- **Mide decision quality, no retrieval.** Si tu sistema tiene 90% retrieval y 75% decisión, el problema no es búsqueda — es que la memoria recuperada es ruidosa o irrelevante. Atacar ese gap pide reflection + scoring de relevancia + curación humana, no más embeddings.
- Empieza ya con narrativa de memory safety. OWASP ASI06 va a entrar en RFPs enterprise en H2 2026. Audit trail + provenance + capacidad de borrar memorias específicas no son features avanzadas — son tabla de apuestas.
- Vigila Anthropic Dreaming + ChatGPT Memory. Si los grandes labs estandarizan memoria nativa con API extensible, las capas third-party (Mem0/Zep/Supermemory) van a tener que reposicionarse rápido. No es escenario hipotético: ya está pasando.
Referencias
Papers fundacionales
- Sumers, Yao, Narasimhan, Griffiths — Cognitive Architectures for Language Agents (CoALA) (sept 2023, versión final mar 2024): https://arxiv.org/abs/2309.02427
- Packer, Wooders, Lin, Fang, Patil, Stoica, Gonzalez — MemGPT: Towards LLMs as Operating Systems (2023): https://arxiv.org/abs/2310.08560
- Lewis et al. — Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (NeurIPS 2020): https://arxiv.org/abs/2005.11401
- Liu et al. — Lost in the Middle: How Language Models Use Long Contexts (2023): https://arxiv.org/abs/2307.03172
- Park, O'Brien, Cai, Morris, Liang, Bernstein — Generative Agents: Interactive Simulacra of Human Behavior (2023): https://arxiv.org/abs/2304.03442
- Shinn, Cassano, Berman, Gopinath, Narasimhan, Yao — Reflexion: Language Agents with Verbal Reinforcement Learning (NeurIPS 2023): https://arxiv.org/abs/2303.11366
- Wang, Xie, Jiang, Mandlekar, Xiao, Zhu, Fan, Anandkumar — Voyager: An Open-Ended Embodied Agent with Large Language Models (2023): https://arxiv.org/abs/2305.16291
Sistemas de memoria 2024-2026
- Asai, Wu, Wang, Sil, Hajishirzi — Self-RAG (ICLR 2024): https://arxiv.org/abs/2310.11511
- Zhong et al. — MemoryBank: Enhancing LLMs with Long-Term Memory (2023): https://arxiv.org/abs/2305.10250
- Rasmussen, Paliychuk, Beauvais, Ryan, Chalef — Zep: A Temporal Knowledge Graph Architecture for Agent Memory (2025): https://arxiv.org/abs/2501.13956
- Xu, Liang, Mei, Gao, Tan, Zhang — A-MEM: Agentic Memory for LLM Agents (NeurIPS 2025): https://arxiv.org/abs/2502.12110
- Chhikara, Khant, Aryan, Singh, Yadav — Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory (ECAI 2025): https://arxiv.org/abs/2504.19413
- Fountas et al. — Human-inspired Episodic Memory for Infinite Context LLMs (EM-LLM) (sometido jul 2024, aceptado ICLR 2025): https://arxiv.org/abs/2407.09450
- Du — Memory for Autonomous LLM Agents: Mechanisms, Evaluation, and Emerging Frontiers (2026): https://arxiv.org/abs/2603.07670
Benchmarks
- Maharana, Lee, Tulyakov, Bansal, Barbieri, Fang — LoCoMo: Evaluating Very Long-Term Conversational Memory of LLM Agents (2024): https://arxiv.org/abs/2402.17753
- Wu et al. — LongMemEval (ICLR 2025): https://arxiv.org/abs/2410.10813
- BEAM: Beyond a Million Tokens (2025): https://arxiv.org/abs/2510.27246
Memory safety
- Remembering More, Risking More (2026): https://arxiv.org/abs/2605.17830
- Persistent Compromise of LLM Agents via Poisoned Experience Retrieval (MemoryGraft) (dic 2025): https://arxiv.org/abs/2512.16962
- OWASP — Top 10 for Agentic Applications (publicado dic 2025, ASI06 — Memory & Context Poisoning): https://genai.owasp.org/
Productos y empresas
- Mem0: https://mem0.ai · https://github.com/mem0ai/mem0
- Zep / Graphiti: https://www.getzep.com · https://github.com/getzep/graphiti
- Letta (ex-MemGPT): https://www.letta.com · https://github.com/letta-ai/letta
- Cognee: https://www.cognee.ai · https://github.com/topoteretes/cognee
- Supermemory: https://supermemory.ai
- Memori (GibsonAI): https://github.com/GibsonAI/memori
- LangMem: https://langchain-ai.github.io/langmem/
- ReMe (ex-MemoryScope, Alibaba): https://github.com/modelscope/MemoryScope
- Anthropic Memory Tool + Dreaming: https://claude.com/blog/context-management
- Google Vertex AI Memory Bank: https://docs.cloud.google.com/agent-builder/agent-engine/memory-bank/overview
Críticas y comparativas independientes
- Zep — Lies, Damn Lies, Statistics: Is Mem0 Really SOTA in Agent Memory? (mayo 2025): https://blog.getzep.com/lies-damn-lies-statistics-is-mem0-really-sota-in-agent-memory/
- Zep — Announcing a New Direction for Zep's Open Source Strategy (abr 2025, deprecación de Community Edition): https://blog.getzep.com/announcing-a-new-direction-for-zeps-open-source-strategy/
- Juan Dastic — I Benchmarked Graphiti vs Mem0: The Hidden Cost of Context Blindness in AI Memory (dev.to): https://dev.to/juandastic/i-benchmarked-graphiti-vs-mem0-the-hidden-cost-of-context-blindness-in-ai-memory-4le3
- Calvin Ku — From Beta to Battle-Tested: Picking Between Letta, Mem0, Zep for AI Memory (Medium, may 2025): https://medium.com/asymptotic-spaghetti-integration/from-beta-to-battle-tested-picking-between-letta-mem0-zep-for-ai-memory-6850ca8703d1
- Vectorize — Mem0 vs Zep: https://vectorize.io/articles/mem0-vs-zep
Internal Research — Intelia. Si quieres profundizar en un sub-tema concreto (decision quality scoring, sleep-time compute, memory poisoning, o un vendor específico), pidamos otra nota dedicada.