Nos come la IA #10 — Pensé que me habían hackeado
Pensé que me habían hackeado la cuenta de Anthropic. Resulta que el problema era yo, mi factura, y un mercado de IA que está empezando a parecerse al Uber de 2014.
Estaba ya preocupado al empezar la mañana. Llevaba ese día consumido casi un 30% de mi cuota semanal de Claude Code. Normalmente me dura cinco días al 20% diario, así que ese 30% me había mosqueado. A media tarde me meto en una llamada con Jaime, no estoy ejecutando nada, miro de reojo el contador — y en cuarenta y cinco minutos he pasado del 50 al 100. Cero tokens. Tres horas hasta el siguiente reset.
Lo primero que pasa por mi cabeza es: me han hackeado la cuenta. La segunda: no tengo IA durante tres horas, ¿qué hago ahora?. Las dos cosas al mismo tiempo, y ninguna de las dos era buena.
Pensé que me habían hackeado
Le digo a Jaime que le doy un minuto. Cambio la contraseña de Anthropic. Reviso las sesiones activas — me figura una en Linux desde hace días, pero no me termino de aclarar de cómo funcionan los tokens de autorización de Claude Code, así que tampoco me puedo fiar. Me voy a Twitter, me voy al GitHub público de Anthropic, busco "tokens consumed", "abnormal usage". Encuentro algunos hilos pero nada definitivo.
La parte irónica empieza ahí: para diagnosticar por qué Claude se me ha quedado sin tokens, necesito una IA. Le pido a Codex — mi otra suscripción de doscientos al mes — que me ayude a redactar un issue para el repo de Claude Code. Lo importante que tengo claro es que los tokens consumidos en mi sesión local no cuadran con el bajón de cuota. Si yo no he ejecutado nada, alguien me lo ha gastado, o el contador de Anthropic está roto.
Mientras escribo el issue, encuentro a más gente reportando lo mismo. Y veo otra cosa: hace unas semanas, Anthropic reconoció que estaba ajustando los límites de uso para gestionar capacidad. Antes subvencionaba el horario fuera de uso para repartir carga; ahora limita más agresivamente en horas pico. La cuota semanal sigue siendo la misma — pero cómo se distribuye a lo largo de la semana ha cambiado. Una sesión de cinco horas se te puede ir en menos de hora y media si pillas el momento equivocado.
Ya no era hackeo. Era un cóctel: política nueva de Anthropic + mi consumo bestia + algún bug por el medio. Me bajé de versión de Claude Code porque varios usuarios decían que con la última los subagentes se quedaban colgados consumiendo tokens en bucle. No estaba seguro, pero algo había que probar.
A la mañana siguiente abro el portátil. Batería al 7%. No había hecho nada en toda la noche. Pensé que se me había roto la batería. Le pido a Codex que mire qué procesos están corriendo, y aparece la respuesta: una pila de procesos llamados bun consumiendo CPU al máximo. Los ochenta vatios del cargador no daban para alimentar el portátil y la batería a la vez. Resulta que sí, los subagentes de Claude Code se estaban quedando colgados — y mientras dormía, mi CPU les estaba pagando la fiesta. Los tokens se evaporaban solos.
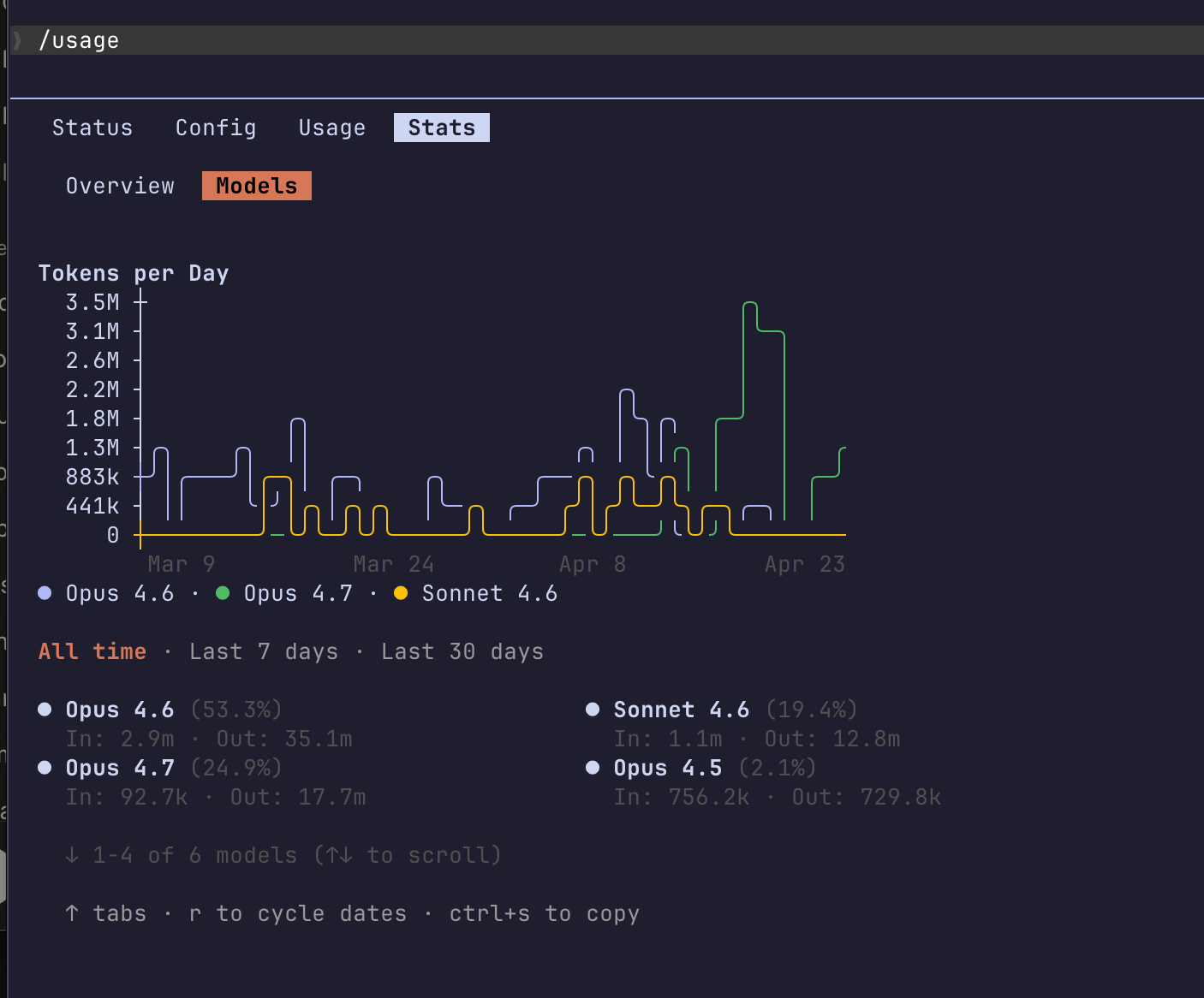
Antes me duraba cinco horas. Ahora hora y media
Lo del horario pico no es paranoia. Lo he comentado con varios amigos que también viven dentro de Claude Code: por la noche todo va más lento, en horas pico la cuota se evapora. Antes me llegaba para una sesión completa de cuatro o cinco horas. Ahora la misma sesión se me come en una hora y media. Mismo trabajo, misma forma de currar, distinta factura.
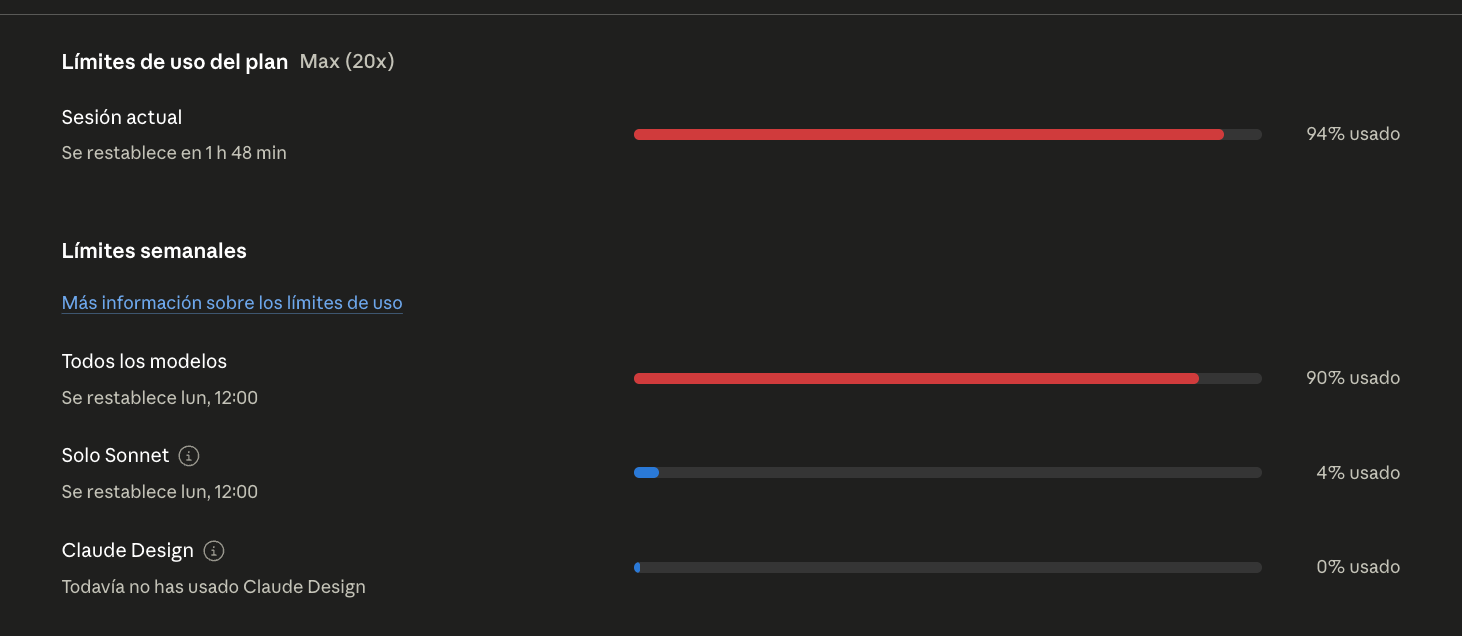
Si la subida sigue así, mi escenario personal está claro: si mañana me suben de cuatrocientos a mil dólares al mes, lo voy a pagar. Mil dólares al mes sigue siendo más barato que un becario, y a día de hoy me da más output del que un becario me daría — aunque me esté volviendo loco. Pero la sensación de que la fiesta está terminando se cuela.
Y hay un detalle que me preocupa más que el precio: cuando me quedé tres horas sin tokens, me di cuenta de lo dependiente que soy. No es que tarde más en hacer las cosas. Es que prácticamente no puedo avanzar. Todos mis flujos pasan por Claude. La IA dejó de ser una herramienta hace meses y se ha convertido en infraestructura. Si me cortan la luz, no escribo a la luz de las velas — me quedo a oscuras.
El momento Uber
La pregunta que me llevo de la semana es si esto es solo un susto o el principio de algo más serio. Andrej Karpathy escribió hace poco una frase que me encajó como un guante: "you can outsource your thinking, but you cannot outsource your understanding". Puedes delegar el pensar — me lo demuestra Claude todos los días. Lo que no puedes delegar es el entender por qué haces lo que haces. Y en una semana en la que la propia herramienta que delega el pensar se me apaga sin avisar, eso pesa distinto.
Mi tesis es que estamos en el momento Uber del 2014. Cuando Uber salió a tu ciudad, te subvencionaba el viaje. Subías al coche, pagabas siete euros lo que en taxi te costaba veinte, y pensabas que era magia. La magia no era el modelo de negocio — era el capital riesgo pagando el descuento para captar mercado. Cuando Uber alcanzó masa crítica, los precios se ajustaron. Eso es lo que está pasando con la IA: hoy te cobran cuatrocientos al mes lo que probablemente cuesta más, porque están comprando tu lealtad a sangre fría.
¿Qué refuerza la tesis? Los números de Anthropic. Esta semana se ha conocido que está a punto de cerrar una ronda de cincuenta mil millones a una valoración de novecientos mil millones de dólares — pasaría a valer más que OpenAI. Su run rate ha pasado de nueve mil millones al cierre de 2025 a cuarenta mil millones ahora mismo. No he visto un fenómeno igual en la historia. Esto no es una empresa creciendo: es un producto que la gente necesita, como el agua o la electricidad, y por el que están dispuestos a pagar lo que haga falta.
Y eso me da miedo. Miedo porque significa que la ventana de oportunidad para los que estamos construyendo encima se está cerrando. Cada empresa con dinero en el banco está metiendo IA en sus flujos a la velocidad que puede. Cuando todo el mundo lo tiene en el top de la agenda, dejar de hacerlo no es una opción — y eso tira de la demanda hacia arriba sin freno.
¿Qué tira en sentido contrario? Dos cosas. La primera, la presión competitiva: Gemini, Anthropic y OpenAI se están peleando por los mismos usuarios, así que en algún momento alguno va a tirar el precio. La segunda, los modelos chinos. Esta semana DeepSeek lanzó V4 open-source y casi iguala a Claude Opus en SWE-bench — a una sexta parte del coste. Lo puedes descargar y ejecutar tú en tu propio servidor. Es una salida que yo personalmente todavía no he probado — sigo usando lo mejor del mercado en cada momento — pero la veo cada día más cerca.
El código es la sombra
Esta semana comí con un amigo founder, también metido hasta el cuello en IA. En la sobremesa me suelta una frase que llevaba meses dándome vueltas sin saber cómo expresarla: "el programa no es el código. El programa es la idea. El código es la sombra." No fue una revelación — fue una cristalización. La intuición ya la tenía; me faltaba la frase exacta para clavarla.
Lo que me está diciendo es: si codificar se está volviendo gratis — y se está volviendo gratis — lo escaso pasa a ser la capa de arriba. La idea, el concepto, la decisión de qué construir y por qué. Los modelos van a seguir mejorando. Lo que hoy te cuesta cuatrocientos al mes hacerlo, en doce meses te costará cincuenta. Lo que hoy es un modelo premium en seis meses será un modelo de gama media. La curva del precio del cómputo va hacia abajo. La curva de tu capa conceptual no.
Es exactamente lo opuesto de cómo hemos trabajado los últimos diez años. Hasta ahora la idea era barata y la implementación cara — diseñar un producto en una pizarra te llevaba una hora, montarlo te llevaba seis meses con cinco ingenieros. Ahora la implementación se está colapsando en horas, pero la idea sigue costando lo mismo. Pensar bien no se ha vuelto más barato.
Conecta con mi miedo de dependencia. Si lo único que pago hoy son tokens, y los tokens son la pieza que se está abaratando, lo que tengo que proteger no es mi acceso a Claude. Es la capa que está por encima — los conceptos, el contexto, las decisiones, lo que define cómo opera mi empresa. Eso es lo que no se evapora si Anthropic me sube el precio.
Lo hablé con Jaime al día siguiente: ¿qué pasaría si tirásemos Intelia entera y la rediseñáramos desde cero, conceptualmente, y le pidiéramos al modelo que la montase? No es una propuesta seria a corto plazo, pero es un pensamiento útil. Si lo escaso es la arquitectura conceptual, todo lo que invertimos en ella es valor que se queda. Todo lo que invertimos en código es ya, de hecho, sombra.
Y precisamente por eso, lo que llevamos haciendo Jaime y yo en Intelia desde hace semanas es lo siguiente: construir esa arquitectura conceptual de forma sistemática. Le hemos puesto un nombre — el ETL del cerebro de Intelia — y un diseño.
El ETL del cerebro de Intelia
En el último post conté que mi trabajo ya no es programar — es curar contexto. Esta semana hemos puesto eso sobre la mesa con nombre y arquitectura, y hemos empezado a tomárnoslo en serio como pieza fundamental de la empresa, no como un proyecto secundario.
La idea es construir la arquitectura conceptual de Intelia junto con la IA. No para la IA — con ella. Hacemos extracción de cómo pensamos Jaime y yo a partir de las propias conversaciones que mantenemos con Claude, y vamos curando lo que sale en distintas capas de abstracción. Y aquí, siempre que pienso en esto, me viene a la cabeza el Pensieve de Harry Potter — sacar los pensamientos de la cabeza para mirarlos por fuera, ordenarlos, comparar versiones, recombinarlos. Es exactamente eso, pero con el modelo como ayudante.

El problema lo tenemos como cualquier empresa pequeña que va rápido: la información está repartida por mogollón de sitios. Reuniones que no se transcriben. Brainstorms en pizarras de Miro que nadie revisita. Pull requests con discusiones que mueren cuando se hace merge. Decisiones tomadas en una llamada de quince minutos que nunca se escriben en ningún sitio. Y luego, encima, las propias sesiones con Claude Code, donde se discuten conceptos importantes que también desaparecen cuando cierro la pestaña.
Hemos empezado a pensarlo como un proceso ETL — extract, transform, load — pero del cerebro de la empresa. Una analogía industrial para un problema que no es industrial. Pintado, queda así:
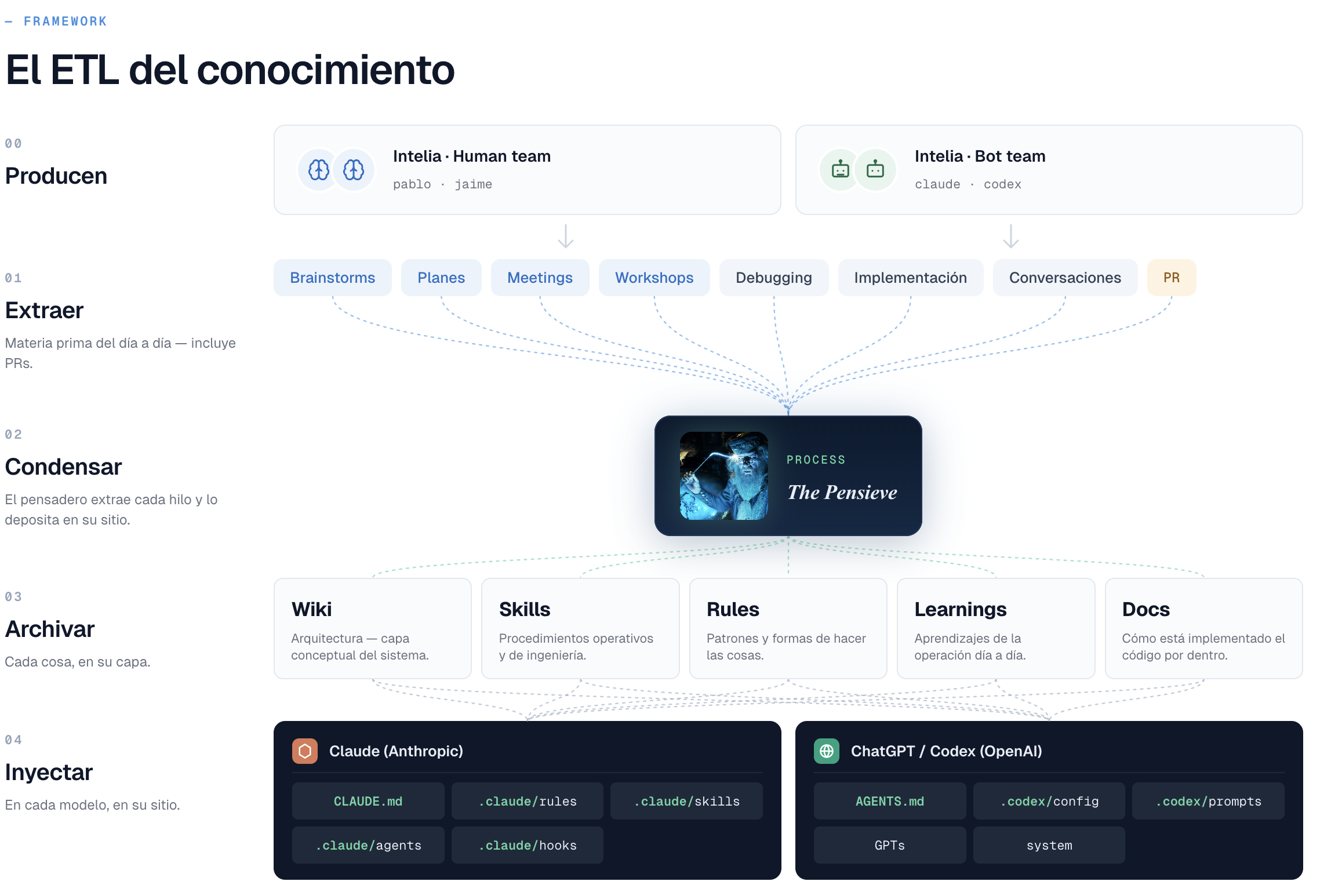
El proceso tiene cinco fases.
00 · Producen. Hay dos equipos generando contexto a la vez: el humano (Jaime y yo) y el bot (Claude, Codex). Distinguirlos importa porque el output bruto de uno y otro es muy distinto, y el ejercicio de extracción cambia. El humano trae intuición, prioridades, juicio. El bot trae estructura, exhaustividad, capacidad de articular en frío lo que el humano deja a medias.
01 · Extraer. La materia prima del día a día — brainstorms, planes, meetings, workshops, debugging, implementación, conversaciones con clientes, pull requests. Todo eso genera información valiosa que de momento no estamos capturando con disciplina. La pierdes en el momento en que terminas la reunión o cierras la pestaña.
02 · Condensar. Aquí entra el Pensieve. Cogemos lo que ha salido de cada actividad, sacamos los hilos importantes, descartamos el ruido. Es el paso que se hace con la IA: Claude detecta duplicados que se nos escapan, propone categorizaciones, identifica ideas contradictorias entre dos sesiones distintas. Pero la decisión final — qué se promociona, qué se descarta, qué se reescribe — la tomamos Jaime y yo en sesiones de revisión. La curaduría no es delegable.
03 · Archivar. Cada hilo condensado va a su capa, y cada capa cambia a velocidad distinta. Wiki es el diseño conceptual del sistema — qué somos, qué principios mantenemos, qué decisiones nos definen sea cual sea el código que tengamos hoy. Skills son procedimientos operativos: cómo hacemos las cosas. Rules son patrones y formas de hacer — convenciones, estilos, decisiones que se aplican una y otra vez. Learnings son aprendizajes de la operación día a día, observaciones que han probado ser ciertas con el tiempo. Y Docs es la documentación del código tal y como está implementado hoy. Separarlas es lo que evita que el día que cambies de implementación tengas que rescribirlo todo.
04 · Inyectar. Aquí es donde el conocimiento aterriza en los formatos que los modelos entienden cuando trabajan. Para Claude Code: CLAUDE.md, las rules, los skills, los subagentes, los hooks. Para Codex/ChatGPT: AGENTS.md, configuración, prompts, GPTs personalizados. Si nuestra documentación no aterriza en estos sitios, los modelos no la ven cuando trabajan — y por mucho que la tengamos bonita en una wiki, da igual.
Lo que más nos cuesta hoy es todo. No somos consistentes extrayendo. La organización no es estable — la misma información vive en tres sitios. No habíamos hecho el ejercicio conceptual de cómo organizarlo, así que ahora lo estamos haciendo en caliente. El deep dive de cómo lo estamos planteando se merece su propio post — que probablemente caiga la semana que viene.
Pero hay un beneficio que ya hemos visto claro y que me importa por cómo conecta con todo lo anterior: si centralizo el conocimiento conceptual de Intelia en mi propio repo, dejo de depender del modelo concreto que lo ejecute. Hoy uso Claude Code. Mañana podría usar Codex. Pasado, un modelo open-source corriendo en mi máquina. El harness cambia. La capa conceptual no — porque vive en mi código. Eso es independencia. Esa es la única forma de que el día que Anthropic me suba la factura a mil, o el día que me la corte directamente, la cosa siga funcionando.
Si te quedaba alguna duda de qué le diría a alguien que está donde yo estaba hace seis meses — emocionado, metiéndole IA a todo sin pensar mucho en el coste — la respuesta es: sigue haciéndolo. A pesar del susto de los tokens, a pesar de los cuatrocientos al mes, a pesar de la paranoia de que te puedan hackear. La IA va a ser uno de los ingredientes fundamentales del trabajo y de la sociedad en los próximos diez años. Hay que estar en la cresta de la ola. Pero estar en la cresta no es lo mismo que ser dependiente — y esa diferencia se decide ahora, en la capa que tú construyes encima.
Esta semana, atrapado tres horas sin tokens, me acordé de algo que dije en una llamada con Jaime: "hay veces que cuando estás delante del ordenador viendo cómo trabaja la IA, te deshaces el cerebro. Es mejor ir a correr y pensar, o sentarte con una hoja en blanco." Quizá lo único bueno de la cuota agotada fue que me obligó a hacer eso.
You can outsource your thinking. But you cannot outsource your understanding.
Nos come la IA es un newsletter semanal de Pablo Muniz, cofundador de Intelia. Si te ha gustado, compártelo con alguien que hable de IA pero no la haya tocado.