Nos come la IA #15 — Si no mides, te la cuelan
Llevar un proceso a un nivel real de automatización es mucho más complicado de lo que parece. Requiere mancharse las manos y asumir que tu intuición te va a engañar. Lo que hemos aprendido en las últimas semanas.

Hay una promesa implícita en todo lo que se habla de IA este año: que automatizar es relativamente fácil. Conectas el modelo, le explicas lo que quieres, y empieza a trabajar. Y es verdad —hasta cierto punto. El problema es lo que viene después.
Llevar un proceso a un nivel real de automatización es mucho más complicado de lo que parece al principio. Requiere mancharse las manos, entender cómo se comporta la IA en condiciones reales, y asumir que tu intuición sobre lo que va a hacer te va a engañar más veces de las que acertará. Las cosas son más complejas de lo que parecen, y a veces la complejidad no está donde esperas.
Os comparto algunas de las cosas que hemos aprendido en las últimas semanas construyendo —y fallando.
Si no mides, te la cuelan
En estas últimas semanas hicimos algo que llevábamos tiempo queriendo hacer: coger nuestro Document Processing Workflow —el proceso que analiza y contabiliza facturas— y correrlo con nueve modelos distintos, midiendo coste real vía LiteLLM y calidad real sobre el mismo conjunto de datos. No precios de tabla. Coste de factura.
El resultado fue contraintuitivo en casi todos los casos.
Primera sorpresa — Gemini 3.5 Flash: el último modelo de Google es el único que mejora el score y en lista es más barato que el modelo actual —$1,50/$9 por millón de tokens frente a $2/$12, un 25% menos. En papel debería ser la elección obvia. Pero en la ejecución real sobre el dataset de regresión salió un 6% más caro que el baseline. ¿Por qué? Genera más tokens de output: responde más, elabora más. Precio por token más bajo; factura por tarea más alta. Curioso.
Segunda sorpresa — GPT-5.4 full y GPT-5.5: en lista son los más caros ($2,50/$15 y $5/$30 frente a $2/$12 del baseline). Deberían salir carísimos. En el run medido por LiteLLM aparecieron más baratos que el modelo actual: GPT-5.5 generó 39.000 tokens de output donde el baseline generó más de 100.000. Razonan internamente y dan respuestas más cortas. Precio por token alto; coste por tarea menor. La misma falacia del revés.
Trade-off calidad / coste registrado — 9 modelos en el mismo pipeline
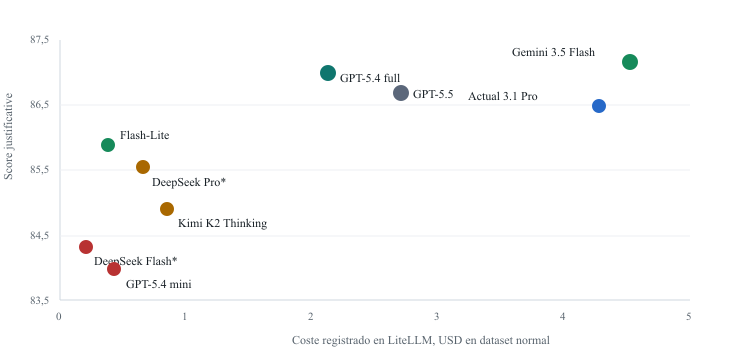
Arriba es mejor calidad; izquierda es menor coste real medido en LiteLLM. Gemini 3.5 Flash queda arriba a la izquierda: mejor score y —en precio de lista— más barato. GPT-5.4 full y GPT-5.5 aparecen en el centro pese a tener los precios de lista más altos, porque generan menos output. Los puntos DeepSeek (*) usan coste recalculado porque LiteLLM registró spend=0. Benchmark interno Intelia · Document Processing Workflow · mayo 2026.
Un amigo emprendedor, Miguel, lo llama la falacia del coste por token: mirar la tabla de precios y asumir que eso es lo que pagas por resolver una tarea. No lo es. La factura depende de cuántos tokens genera el modelo para tu tarea concreta, no de cuánto cuesta el token en abstracto.
De este ejercicio salieron cuatro recordatorios. Obvios una vez los ves. Fáciles de olvidar en el fragor del día a día.
Uno: tienes que medir para tu caso específico. Los precios dependen de la tarea. Sin contador no hay verdad, solo suposiciones.
Dos: los modelos más nuevos no son siempre mejores para tu tarea concreta. Y los modelos sin thinking, aunque su precio de lista sea más alto en algunos casos, pueden salir más baratos porque no queman tokens razonando lo que no necesitan razonar.
Tres: la ganancia marginal de los últimos puntos de calidad es muy cara. El gráfico siguiente muestra cuánto cuesta cada punto porcentual adicional de accuracy. A partir de cierto umbral, probablemente sea más eficiente invertir ese dinero en soluciones deterministas o en mejor prompt engineering que en cambiar de modelo.
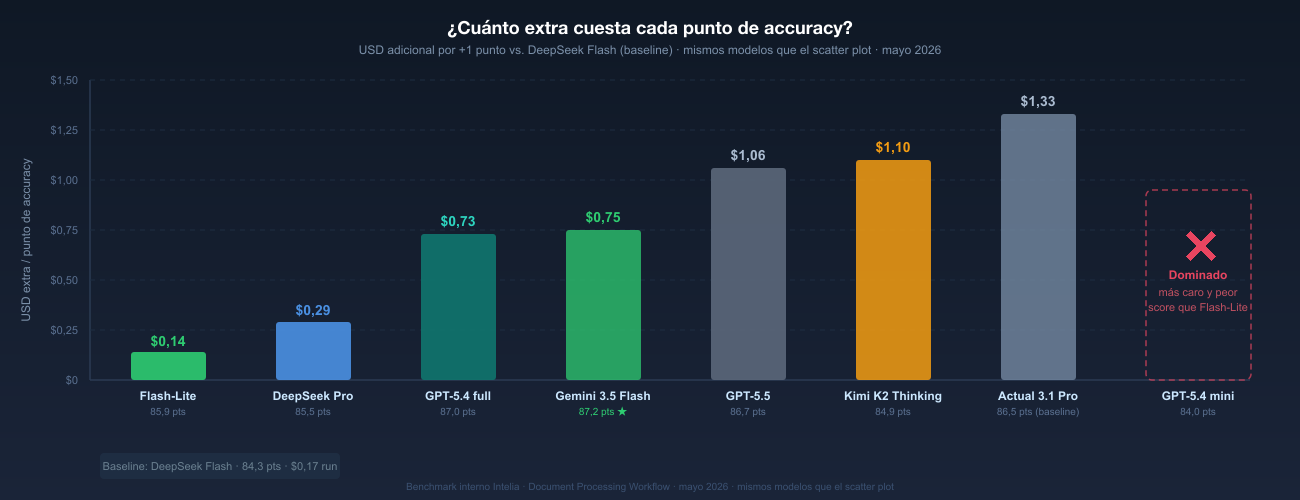
Cuatro: estamos en el 87%. Buena noticia si lo ves como margen de mejora. Mala si lo que quieres es un proceso 100% automatizado —porque ese 13% de error requiere supervisión humana, y eso tiene un coste. La pregunta no es "¿funciona?" sino "¿funciona lo suficientemente bien para quitar al humano del bucle?"
El estado del arte de la IA en producción hoy es este: si no mides, te equivocas. Si no monitorizas, te la cuelan. No porque los modelos engañen, sino porque la intuición sobre precios y calidad falla constantemente.
El precio de la tabla no es el precio real. Y el último 5% de precisión puede costarte más que todo el 80% anterior.
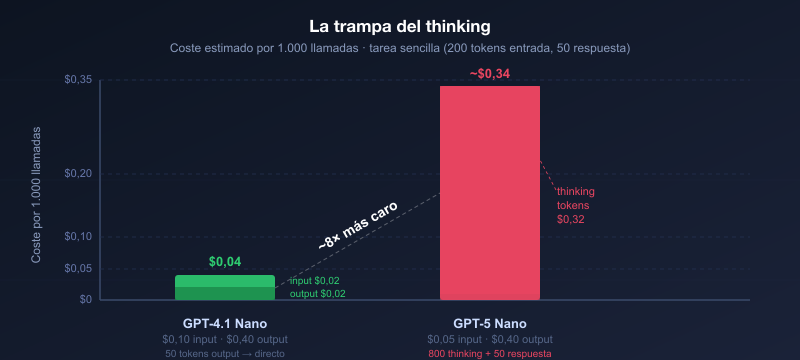
La primera trampa que encontramos incluso antes del benchmark: teníamos GPT-5 Nano puesto para comentarios contables —"el más barato", pensaba yo. GPT-5 Nano: $0,05 de entrada, $0,40 de salida. GPT-4.1 Nano: $0,10 de entrada, $0,40 de salida. Mismo precio de salida. Pero GPT-5 Nano genera 800 tokens razonando antes de escribir los 50 de respuesta. GPT-4.1 Nano va directo. El input más barato, la factura más cara.
El modelo que improvisa donde no debería
Esta misma semana, preparando la revisión semanal de un cliente, el agente tenía que procesar 41 tareas —24 facturas SaaS que llegan automáticamente más 17 pendientes reales. El proceso previsto: un subagente por tarea, en paralelo. Lo que hizo el agente: decidir por su cuenta que 41 subagentes eran demasiados y hacer "un focused pass" directo sobre los 4 que consideró más urgentes. Y encima los resolvió mal.
La doble trampa: primero se saltó el proceso porque creyó que podía optimizarlo. Luego falló en lo que eligió hacer. El agente con más contexto y más capacidad tiene también más tendencia a "mejorar" el proceso por su cuenta —a hacer lo que le parece razonable en vez de lo que le pediste. Y cuando además falla, no tienes ni el proceso correcto ni el resultado correcto. El agente con más contexto y más capacidad tiene también más tendencia a "optimizar" el proceso por su cuenta —a hacer lo que le parece mejor en vez de lo que le pediste. Otro ejemplo: le pedimos a un agente 25 iteraciones para optimizar un eval. Hizo 10 y paró. Sin avisar. El mismo skill de revisión de cliente va de corrido para un compañero sin pedir confirmación, y a mí me para en cada paso. Mismo sistema, mismo modelo, comportamiento completamente distinto. No tenemos explicación clara.
Durante meses, la respuesta intuitiva a esto ha sido "escribir mejores instrucciones". Más detalladas, más estructuradas, más a prueba de tontos. Y tiene un límite. Cuando el proceso es complejo, al agente le cuesta seguirlas. No por falta de capacidad —es que estás pidiéndole que ejecute una receta y él prefiere cocinar.
La conclusión a la que hemos llegado va en la dirección contraria: todo lo que siempre se hace igual va en código. Al modelo solo le queda lo que genuinamente requiere juicio. Cuanto más importante es que el resultado salga bien, menos margen de improvisación le dejas donde no lo necesita.
Anthropic acaba de lanzar algo directamente orientado a esto: Dynamic Workflows. Son scripts JavaScript que orquestan subagentes de forma programática. El flujo está codificado en el script, no vive en la cabeza del modelo turno a turno. Lo mismo que hemos ido descubriendo a base de golpes, convertido en feature.
Los evals: cómo sabes que funciona de verdad
Cuando construyes un sistema de IA para algo complejo, tienes un problema que el software tradicional no tiene: ¿cómo sabes que funciona? No hay un resultado inequívoco. Puedes ver que el agente hace algo, pero ¿lo hace bien? Para eso están los evals: un conjunto de casos reales con la respuesta correcta conocida, contra los que mides el sistema cada vez que cambias algo.
Suena simple. No lo es. Estábamos evaluando un clasificador contable y en la primera pasada el score salió altísimo. Sospechosamente alto. Fuimos a mirar: el modelo tenía la respuesta dentro del contexto de entrada —el tratamiento fiscal ya venía calculado en el input. No estaba resolviendo el problema, estaba copiando la solución. Cuando corregimos eso, el score cayó al 80% y ahí se quedó, fallando siempre en los mismos casos.
Los modelos son muy buenos encontrando atajos. Si les das la oportunidad de hacer trampa, la aprovechan —no por malicia, sino porque optimizan para dar la respuesta correcta, no para aprender el razonamiento. Por eso el diseño de los evals es crítico y fácil de hacer mal: separar bien los datos de entrenamiento de los de evaluación, no meter la respuesta dentro de la pregunta, y usar un segundo agente cuyo único trabajo sea buscar los fallos del primero.
Lo del adversarial es lo más revelador. Jaime encadenó dos agentes: uno que hace el trabajo contable, otro cuyo único cometido es demostrar que el primero se equivocó. El resultado: siempre encuentra algo. Cada caso. El que ejecuta nunca es suficientemente detallista porque optimiza para completar, no para criticar. El que revisa, al optimizar para refutar, ve exactamente lo que el otro no vio. Revisar y hacer son funciones cognitivas distintas, incluso en IA.
Dos arquitectos, el mismo plano
Una última cosa que no sé muy bien cómo interpretar. Jaime y yo llevamos semanas trabajando en paralelo en el mismo problema —el sistema de planificación contable de V3— cada uno con sus agentes, sin comparar notas. Esta semana pusimos los dos diseños en común. Eran sospechosamente similares.
O los modelos se copiaron entre sí durante el desarrollo —posible, dado que ambos leemos el mismo contexto de empresa—, o los modelos piensan de forma parecida porque los dos usamos Opus y Opus tiene una prior fuerte sobre cómo debería verse un lenguaje de planificación contable. En cualquier caso, la conclusión incómoda es que nuestra contribución a nivel de arquitectura puede ser menor de lo que creemos. No sé explicarlo del todo. Pero es una señal que no voy a ignorar.
Lo que está pasando esta semana
¿Los agentes necesitan más software de terceros?
Jensen Huang en Computex lo planteó así: cuantos más agentes existan, más herramientas de software necesitarán. Los SaaS stocks rebotaron un 6,4% ese día. Berkshire Hathaway metió 10.000 millones en Google para financiar infraestructura de IA.
No estoy seguro de comprar la tesis de Jensen. Lo que hemos aprendido construyendo es que todo lo que puede hacerse determinista, se hace determinista —y eso implica código propio, no necesariamente herramientas de mercado. Si los agentes acumulan suficiente contexto de dominio para construir sus propias herramientas, la pregunta es si el precio del software de terceros aguantará. Lo que sí parece claro: las empresas más pegadas al sustrato —energía, data centers, memoria— son las que están capturando valor ahora. El resto todavía está por ver.
La moat son tus datos, no tu modelo
Revolut entrenó un modelo llamado PRAGMA sobre 40.000 millones de eventos bancarios propios. Resultado: 20% mejor detección de fraude, 65% mejor recall. Stripe pasó del 59% al 97% en detección de fraude usando sus propios datos de transacciones.
La moat no es el modelo —ese lo tiene cualquiera en cuanto sale la siguiente versión. La moat son los datos que nadie más puede replicar porque los has generado operando durante años en tu dominio. Para las empresas que ya los tienen, ventaja enorme. Para las que no, construirla desde cero es caro y lento.
La IA no despide programadores, despide a los junior
El empleo de desarrolladores de 22-25 años cayó casi un 20% desde su pico de 2022. Los mayores de 30 en los mismos sectores crecieron. La IA no está reemplazando a los programadores en general —está eliminando los roles de código boilerplate, testing rutinario y bugs triviales. Los roles de diseño de sistemas, evaluación de modelos e infraestructura de IA están en escasez.
Es el mismo patrón de siempre: la IA baja el coste de ejecutar, no de decidir qué ejecutar.
Por dónde empezar
Si alguien me pregunta cómo empezar a construir con IA de verdad, lo primero que diría es: el modelo es la parte fácil. Lo difícil son tus datos y el conocimiento de tu dominio.
Lo que le da valor a un sistema de IA no es el modelo que uses —eso lo tiene cualquiera— sino lo que sabes de tu negocio y la calidad de los datos que le puedes dar. El modelo de Revolut es mejor que el de la competencia porque tiene 40.000 millones de transacciones propias y años de conocimiento del dominio financiero. Eso no se compra.
El segundo problema práctico: conectar la IA a tus herramientas. Si tu SaaS o tu ERP tiene un conector estándar, enchufas y listo. Si no —y muchos no lo tienen— tienes que construirte la integración tú mismo. Y eso no siempre es sencillo, sobre todo si no eres técnico. Ahí es donde se atasca la mayoría. No en elegir el modelo correcto, sino en conseguir que el modelo vea los datos correctos.
Una vez tienes eso: diseña automatizaciones pequeñas, mide desde el primer día, y acepta que esto es ingeniería. El modelo es la parte más visible. El resto —los datos, las integraciones, los evals, el código determinista que sostiene todo— es la parte que hace que funcione. Y eso nadie te lo da hecho.
Nos come la IA es un newsletter semanal de Pablo Muñiz, cofundador de Intelia. Si te ha gustado, compártelo con alguien que hable de IA pero no la haya tocado.