un framework para automatizar empresas
Un modelo para construir negocios donde la IA hace el grueso del trabajo — sin convertirse en una caja negra ni colapsar en complejidad.
En Intelia llevamos tiempo cocinando esto. Empezó hace meses intentando romper procesos de negocio en sub-procesos manejables, y ha ido decantando en el modelo que recoge este documento. La hipótesis que lo motiva es directa: una compañía se compone de procesos — operativos y de decisión — y si somos capaces de automatizar procesos de forma sistémica, podemos automatizar compañías enteras. Al menos en todo lo que no requiera interacción humana física.
Una función de transferencia (FT, en corto) es la representación matemática de un sistema que toma un input y produce un output según una caracterización propia. Es el término que vamos a usar para hablar de cualquier trozo del negocio — al nivel que sea, ya sea un proceso operativo o uno de decisión.
§ 1
Un proceso de negocio es una función de transferencia. Tiene una entrada, una salida y, entre medias, una caracterización propia — el cómo — que es precisamente lo que vamos a descubrir y optimizar. Da igual el dominio: "facturar a un cliente", "cerrar el mes contable", "onboardear un proveedor", "contestar una consulta de soporte": todos se modelan con el mismo lenguaje.
y = H(x; θ) — lo que sale (y) es lo que entra (x) transformado según la caracterización del sistema (H) y su configuración (θ).
Función de transferencia
p. ej. cerrar el mes contable
Cada FT lleva un Config. No es un input en sentido estricto — los inputs varían en cada ejecución; el Config se reutiliza entre ejecuciones del mismo proceso. Es información de contexto que la FT necesita para razonar de forma consistente sobre cualquier input que reciba:
Dicho de otra forma: si una skill es "el manual de procedimiento", el Config es qué manuales tiene a mano esta FT para hacer su trabajo. Cuando llega un input nuevo, el Config sigue siendo el mismo; lo que cambia es lo que el sistema ve.
§ 2
Pocos procesos de negocio reales se resuelven de una pasada por un LLM frontera. La FT gorda del negocio no es un bloque monolítico: es una secuencia de FTs hijas encadenadas, cada una con su entrada, su salida y su Config propio. Descomponer en sub-procesos tiene sentido por tres razones que vienen casi gratis con el modelo:
razón 1
Cada FT tiene que ser lo bastante pequeña para que un LLM frontera, con sus tools, la pueda resolver sin perderse.
razón 2
Si todo es un único bloque, no sabes dónde falla. Romper permite medir cada decisión por separado y aislar qué se rompe cuando algo se rompe.
razón 3
Cada FT se afina por su cuenta — con su propio dataset golden y su propio objetivo de coste/accuracy/latencia. No tienes que reentrenar el negocio entero para mejorar un paso.
FT A
FT B
FT C
FT D
Composición matemática estándar: H = H_D \circ H_C \circ H_B \circ H_A. Decidir cómo descompones es decidir la arquitectura: cualquier corte impone una opinión sobre los pasos del proceso, los handoffs y qué información viaja entre FTs. No hay descomposición neutra. Lo asumimos y seguimos.
§ 3
Dentro de una FT pueden vivir distintos modelos. El contenido varía:
Por simplificar, usamos un modelo básico de referencia: capa determinista previa + capa no-determinista de decisión. Es el patrón más común para procesos que aún no están del todo destilados, y es donde vive la mayor parte del trabajo de optimización que viene después.
Reglas y filtros que actúan como shortcuts: cosas que el sistema ya aprendió y no necesita re-derivar cada vez. Atrapa los casos triviales, formatea, normaliza, enriquece — prepara y simplifica el input para que la siguiente capa tome una mejor decisión.
Un LLM razona sobre el input ya preparado y aplica el Config (skills, memoria procedimental, contexto) para tomar la decisión que no puede expresarse con reglas duras.
El reparto entre capas se mueve. No es estático. Cada iteración del loop diario empuja cosas de la capa 2 a la capa 1: lo que era ambiguo se vuelve regla, lo que requería razonamiento se vuelve shortcut. La FT se calcifica.
determinista (filtros + shortcuts) · no-determinista (decisión LLM)
§ 4
Automatizar un proceso es, primero, descomponerlo (§ 2). Y después, pasar cada sub-FT por cuatro fases: descubrimiento, optimización, promoción y re-optimización.
discovery
Ponemos un LLM frontera — el modelo más caro y capaz disponible — a ejecutar la FT end-to-end. Recibe el input, lleva su Config, accede a las herramientas y produce el output. Es ineficiente, lento y comete errores. Pero genera ejecuciones reales que podemos analizar.
Otro LLM evaluador clasifica cada output como correct, doubt o failed. Las dudas escalan a un reviewer: idealmente un LLM más caro con capacidad de razonamiento y mucho contexto, alternativamente un humano. Los casos resueltos se quedan como golden dataset.
Doubt = donde el LLM evaluador no puede asegurar si la respuesta es correcta o incorrecta. Es la materia prima de la siguiente fase.
optimization
Un modelo de 2ª capa — el auto-optimizador — observa todas las ejecuciones del modelo frontera y trata de descomponer la FT en una parte determinista y otra no-determinista con un LLM mucho más barato. Va iterando contra el golden dataset hasta que llega al objetivo o agota su budget.
€ Coste / run
tokens, llamadas a tools, infra
✓ Accuracy
contra el golden dataset
⏱ Latencia
tiempo total end-to-end
Estas son las estándar. Cada FT puede añadir métricas ad-hoc según su dominio: tasa de fallback a humano, drift respecto a una distribución conocida, métricas de negocio acopladas a la decisión. No se prescriben.
Side effect importante: durante el análisis del comportamiento del frontera, el sistema va destilando aprendizajes generales que eventualmente alimentan decisiones de mayor nivel — cambiar la arquitectura, romper FTs, crear FTs nuevas, modificar procedimientos. Ese flujo lo desarrollamos en el § 5.
promote
La FT optimizada entra en producción. Sigue generando outputs; el LLM evaluador sigue clasificándolos. Los casos nuevos amplían el golden dataset y alimentan la siguiente re-optimización.
re-optimize ↻
Cada noche, cada semana, cada cierto tiempo — el auto-optimizador vuelve a entrar sobre los runs nuevos. Cada vuelta calcifica más reglas, refina más prompts, mueve más casos a la capa determinista. Pasos 3 y 4 son el latido continuo del sistema.
§ 5 · en producción
Esto no es teoría. En Intelia tenemos un pipeline así corriendo en producción para procesar facturas reales: las recibe por email, WhatsApp, web o sync inverso de Holded, las clasifica, extrae, valida y las acaba sincronizando con el ERP. Mirado en bruto son 13 pasos orquestados por Temporal. Mirado a través del framework, son 6 FTs encadenadas.
Visto desde arriba, el proceso entero es una sola caja: entra un documento de cualquier canal, sale un asiento contable sincronizado con Holded.
Contabilizar documento
v2d accounting
Cada sub-FT tiene su propio Config (skills, plantillas, reglas de dominio) y produce un snapshot estructurado que es input verificable de la siguiente. La cadena es de izquierda a derecha:
1. Ingerir
2. Clasificar
3. Extraer
4. Promover
5. Revisar
6. Sincronizar
| FT | Qué hace | Anatomía | Config |
|---|---|---|---|
| 1. Ingerir | Recibe el archivo de cualquier fuente, deduplica por hash, valida MIME, recorta si es PDF largo. | determinista | canales de origen, límites de archivo, política de dedup |
| 2. Clasificar | LLM multimodal mira el documento y decide tipo: factura, recibo, nómina, otros (+ 17 subtipos). | no-determinista | skills (cómo identificar cada tipo), taxonomía, ejemplos del dominio |
| 3. Extraer | LLM saca proveedor, NIF, fechas, líneas, impuestos. Validación de sumas y formato. Enriquece con VIES y currency. | no-det → det | schema de campos esperados, tasas de IVA legales, APIs externas (VIES, BCE) |
| 4. Promover | Convierte el StructuredDocument en un Justificante con su propio ciclo de vida. Crea entidades fiscales, detecta duplicados (edges), auto-asigna cliente si hace falta (LLM). | det + no-det opcional | reglas de matching de proveedores, política de tax entities, locks de concurrencia |
| 5. Revisar | Tres checks paralelos: errores de validación, riesgo fiscal, compliance de retención. Cierra con status: READY_TO_SEND o HUMAN_REVIEW. | determinista | reglas de riesgo fiscal, tablas de retención, política de auto-aprobación |
| 6. Sincronizar | Empuja el justificante a Holded vía API. Reconcilia si ya existía. Maneja errores y reintentos. | determinista | mapeo a estructuras de Holded, reglas de reconciliación, política de retry |
Las sub-FTs no comparten anatomía interna — tal como decía el § 3, el patrón básico es una guía, no una receta. Dos ejemplos reales del pipeline lo demuestran:
Casi inexistente. Solo descarga del storage y pasa al LLM. Aquí no hay nada que calcificar todavía: la decisión es "qué tipo de documento es esto" y depende de la variedad infinita de formatos del mundo real.
LLM multimodal mira la imagen/PDF y devuelve el tipo + descripción + contexto. El 90% del trabajo vive aquí. Si el documento no encaja en una clase soportada, se descarta el pipeline entero.
LLM multimodal extrae todos los campos: proveedor, NIF, fechas, líneas, importes, IVAs. Es la parte ambigua — cada factura tiene un layout distinto.
Validación de sumas (líneas = base imponible, IVA = base × tipo), enriquecimiento vía VIES, normalización de NIFs, detección de swap proveedor↔receptor. Reglas duras que se aplican sobre el JSON que sacó el LLM.
Es el modelo "no-det → det posterior" mencionado en § 3: el LLM toma la decisión difícil, las reglas verifican que el output es coherente.
Cada vez que una sub-FT termina, produce un snapshot estructurado que es input verificable de la siguiente. El pipeline tiene cuatro tiers de datos canónicos, y son exactamente los snapshots que el § 2 propone:
tier 1
Archivo físico tal cual entró. Hash, MIME, origen, blob en S3.
tier 2
JSON con campos extraídos, validados y enriquecidos.
tier 3
Justificante con ciclo de vida y status propio.
tier 4
Asiento sincronizado en el ERP.
Cualquier sub-FT puede re-ejecutarse stateless a partir del snapshot del tier anterior — igual en producción que en evals. Si quiero probar una versión nueva de FT.clasificar, le doy los DocumentFile que ya tengo y comparo su output contra los tipos que sacó la versión vieja. Si cambio FT.extraer, le doy DocumentFile + tipo y comparo el StructuredDocument resultante contra el golden dataset. Sin esto, los evals serían irreproducibles.
§ 6
El side effect de la fase 2 (§ 4) tiene su propio circuito. Cada aprendizaje destilado durante la optimización de una FT no se queda en su FT: va a una memoria del sistema que el resto del organigrama puede consultar.
Append-only. Cada FT vuelca aquí lo que aprende: patrones, reglas candidatas, casos límite, fallos. Sin curación, sin formato estricto. Crudo.
Otra FT en sí misma. Procesa el lake periódicamente, identifica patrones de alto nivel y propone cambios fuera de la FT origen.
Actualizar skills y memoria procedimental: el Config de unas u otras FTs se enriquece con lo aprendido.
Re-descomponer la cadena: dividir las FTs que se han hecho demasiado complejas, fusionar las que han convergido, crear nuevas para casos emergentes.
Y por encima de eso, un nivel superior que toma decisiones de alto nivel a partir de los aprendizajes agregados: qué procesos priorizar, cuándo invertir en una nueva FT, qué partes del negocio están listas para automatizarse.
La memoria es jerárquica, no plana. Aprendizajes crudos abajo, procedimientos curados en medio, decisiones arquitectónicas arriba.
§ 7 · bonus
Si todo lo anterior funciona, lo siguiente cae por gravedad: esto es fractal. El extractor del § 5 ya es una FT. La fase 2 del § 4 es una FT que optimiza FTs. Si las FTs pueden ejecutar procesos y los procesos pueden ser "crear una FT", entonces podemos tener FTs que crean FTs.
Cuando el sistema detecta en el lake que un tipo de caso emerge con frecuencia, propone una nueva FT para tratarlo. Cuando una FT se ha vuelto demasiado grande, propone romperla. Cuando dos FTs convergen, propone fusionarlas. La arquitectura misma se vuelve dinámica.
Si conseguimos desbloquear esto, lo que queda es un modelo orgánico que se auto-aprende y se auto-mejora — la empresa entera entendida como un organismo de FTs que se reorganizan solas en función de lo que va llegando por la puerta.
Es la pieza más especulativa de todo el framework. Pero es la consecuencia lógica del resto. Si las primeras cinco secciones se sostienen, esta sale gratis.
§ 8
Hay un puñado de jugadores construyendo algo lo bastante parecido como para hacerse mirar. Conviene situar el framework frente a ellos, no como ejercicio defensivo, sino para entender qué problema resuelve cada cual, qué vocabulario están consolidando y dónde está la cuña diferencial del modelo de FTs.
Es el jugador del espacio que más se parece al modelo de FT — merece detalle. Fundada por Manuel Romero y David Villalón en Valencia. $25M Series A en ago 2025 (Creandum + Forgepoint), inversor estratégico vía joint venture con Santander. Reconocida como "Rising Star" por Deloitte y "Front-Runner" por Gartner en abril 2026. Equipo escalando de 35 a 65 personas. Crece 400% YoY.
Venden "digital workers" auditables a empresa grande. Casos públicos con métricas concretas (no marketing genérico):
La unidad fundamental es la KPU (Knowledge Processing Unit). La analogía de Villalón es directa:
"Think about it as if models were CPUs and the KPU is the GPU for knowledge management and processing."
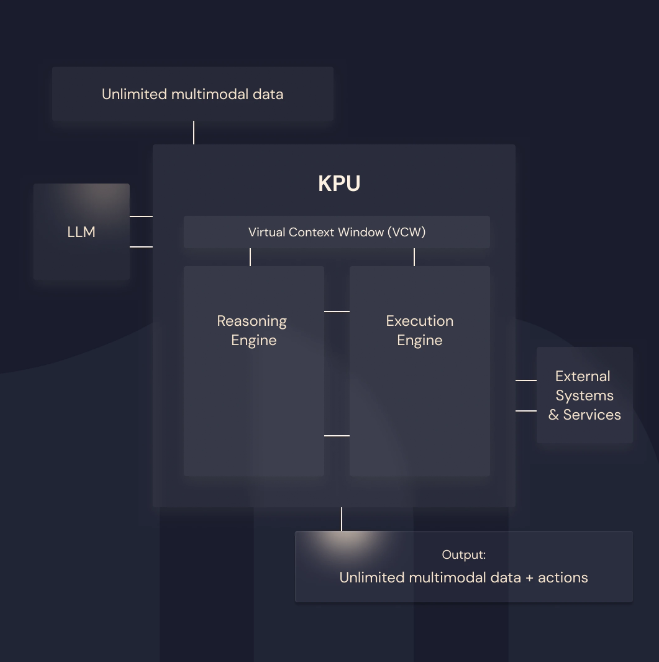
La KPU se compone de tres engines que colaboran. La clave para entenderla es la distinción información ≠ datos:
El KPU está diseñado para que el LLM solo vea información, nunca los datos crudos. Eso es lo que permite manejar volúmenes arbitrariamente grandes sin reventar la ventana de contexto.
donde piensa el LLM
Es el componente donde un LLM construye y mantiene un plan estructurado de ejecución: descompone el objetivo en pasos, decide qué acción tomar a continuación, qué herramienta usar, en qué orden. No es chain-of-thought ad-hoc en un solo prompt; es un loop iterativo donde cada acción va informada por las observaciones anteriores.
Su contexto contiene solo razonamiento: descripciones, planes, decisiones, observaciones de alto nivel. Nunca payload pesado de datos. Eso lo hace barato en tokens y mantiene al LLM enfocado.
donde ocurren las acciones reales
Es el componente que ejecuta físicamente las acciones que el Reasoning Engine decide: corre código en un intérprete (típicamente Python), llama a APIs externas, consulta bases de datos, lee/escribe ficheros. Aquí viven los datos crudos — las facturas, los registros, los documentos.
Cuando termina una acción, devuelve al Reasoning Engine un resumen estructurado de lo que pasó: "ejecutado correctamente, 1.247 registros procesados, 3 duplicados detectados". No le devuelve los 1.247 registros. Le devuelve la información sobre los 1.247 registros.
la membrana entre razonamiento y datos
Es la pieza más original y la que da nombre al resto. El VCW es la capa que orquesta qué llega al Reasoning Engine y qué se queda en el Execution Engine. Filtra, resume, prioriza, indexa. Convierte datos en información digerible para el LLM.
"Information arrives at the Reasoning engine, and data stays at the Execution engine. The LLM context window underlying the Reasoning engine is maintained only with reasoning and not with data, maximizing the value of the tokens."
En la práctica: si el Reasoning Engine necesita revisar 50.000 facturas, el VCW no le pasa las facturas. Le pasa una descripción de la colección (esquema, conteos, estadísticas, ejemplos representativos) y, si hace falta, una API que el Reasoning Engine puede llamar pidiendo subconjuntos concretos: "dame las que tienen importe > 10.000€ y proveedor desconocido". Ese subconjunto se consulta vía Execution Engine, se procesa, y solo el resultado relevante vuelve al razonamiento.
El VCW es lo que permite a Maisa hablar de "unlimited multimodal data" sin que el LLM se ahogue: la ventana de contexto real es finita, pero el sistema presenta al razonamiento una ventana virtualmente ilimitada gracias a esta orquestación.
Los tres engines juntos hacen que la KPU se comporte como una unidad de procesamiento de conocimiento (no de datos), de ahí la analogía CPU/GPU: igual que la GPU paraleliza aritmética para que la CPU no se ahogue, la KPU separa razonamiento de manipulación de datos para que el LLM no se ahogue.
Para FT esto es relevante por dos motivos. Primero, el VCW formaliza con un mecanismo técnico la idea de separar el Config del input que aparece en el § 1 — aunque va más allá: separa información de datos también dentro del input mismo. Segundo, sugiere que en la capa determinista del § 3 hay una sub-función concreta que merece nombre propio: la que prepara los datos crudos convirtiéndolos en información antes de que el LLM razone sobre ellos. Es prior art legítimo en este punto del framework.
Encima de la KPU hay tres conceptos-marca:
El lifecycle de un Digital Worker en Studio es: Onboard → Test → Deploy → Monitor. El citizen developer describe en lenguaje natural y adjunta conocimiento; el sistema genera código a runtime, no flujos pre-encodeados: "generate and execute code at runtime, adapting to each case as it unfolds."
Convergencias: la división determinista (intérprete de código, Execution Engine) + no-determinista (Reasoning Engine) es idéntica a la del § 3. El Chain of Work es un primo del golden dataset trazable. Self-Refine es el latido continuo del § 4.
Divergencias confirmadas a mayo 2026 (tres, todas afiladas):
Análisis crítico externo casi inexistente. El único en profundidad es Robert Maciejko (Medium, paywall): "The KPU, as described by Maisa, straddles the lines between a framework, an architecture, and a system, leaving its exact nature somewhat enigmatic." El espacio agentic AI tiene poca crítica técnica seria todavía — hay hueco editorial.
Plataforma "Agent OS" para customer experience en enterprise (Sonos, ADT, WeightWatchers, SiriusXM). Su arquitectura interna es una constellation of models — 15+ modelos especializados: uno de baja latencia para tool calling, uno de alta precisión para clasificación, uno de contexto largo para política, modelos de tono para la conversación, supervisores que aplican guardrails. Cada modelo hace lo suyo bien; la composición hace el agente.
En marzo 2026 lanzaron dos piezas que, juntas, son el ejemplo más cercano al meta-loop fractal del § 6 ya en producción comercial:
La pareja Ghostwriter + Explorer cubre, en el vocabulario de este framework, el loop 3↔4 del § 4 (re-optimización continua) más una creación human-triggered de FTs nuevas. Lo que no cubre es el meta-loop arquitectural del § 6: detectar autónomamente que una FT nueva hace falta o que la descomposición tiene que cambiar. Y Sierra se excluye explícitamente del dominio backoffice:
"Ghostwriter builds customer experience agents, and if you need agents that operate inside internal tools, manage supply chains, or automate back-office workflows, Sierra isn't the right choice."
Tienen el split determinista/no-determinista más explícito que existe públicamente en este espacio. Su modelo es un three-tier framework:
Y un concepto operativo precioso: shadow mode deployment — el AI corre en paralelo a los procesos viejos y se compara antes de promover.
"Transaction-level tax determination demands deterministic precision; anomaly detection across those same millions of invoices is something only AI can do effectively."
Es la validación más nítida del modelo det/no-det que proponemos en el § 3, con un caso productivo a 500M de transacciones/año. La diferencia clave: Fonoa tiene tiers estáticos, no hay un mecanismo de movimiento entre tiers a medida que el sistema aprende. En FT, la calcificación gradual hace que un caso pueda viajar del tier 3 al tier 1 con el tiempo.
El caso más limpio del "golden dataset como activo central". Cognition construye su negocio entero alrededor de cognition-golden: "realistic evaluations for economically valuable tasks, sometimes on codebases with millions of lines of code."
Estructura: train split + test split — "the train split is used as an autonomous learning environment for self-improvement and the test split for quantitative capabilities evaluation."Simulated users con los que Devin conversa para simular interacción real. Evaluator agents que tienen acceso a las mismas herramientas que Devin (browsing, shell, code editing) para juzgar outcomes autónomamente. Métricas de los evaluadores: "precision and recall on ground truth sets", con revisión humana continua.
Es el contraargumento público al HALP de Maisa: cuando alguien diga "no necesitas datasets etiquetados", la respuesta es Cognition — la empresa de agentic coding más seria del mercado se monta sobre exactamente eso. Limitación: monodominio (software eng), no hablan de descomposición en sub-agentes componibles ni de capas det/no-det internas.
El framework de FT no inventa la rueda en ninguna pieza aislada. Cada una existe ya en alguien. Lo que propone es una intersección que ninguno de los cuatro tiene completa:
Cada jugador tiene una de las tres patas. El framework propone las tres juntas como sistema único — el sistema de gestión del activo golden dataset que se calcifica con el tiempo dentro de una arquitectura de FTs que se reorganizan solas.
§ 9
El framework está deliberadamente incompleto. Hay tres piezas que sé que requieren más cocción antes de soltarlas en producción a gran escala:
Procesos stateful.
La inmensa mayoría de procesos reales son stateful. Tienes una base de datos que cambia, un sistema externo que evoluciona, una conversación que avanza. La idea del snapshot como input (§ 2) resuelve la reproducibilidad, pero no resuelve cómo gestionas el estado en producción: cuándo se hace el snapshot, qué granularidad tiene, cómo se reconcilia si entre snapshot y ejecución el estado real cambió, cómo se versiona. Esta es la pieza menos resuelta.
El meta-loop, en concreto.
FTs que crean FTs es conceptualmente impecable, pero en la práctica es difícil — Google lo intentó con resultados modestos. ¿Cómo evita el sistema generar FTs redundantes? ¿Cómo mide si una nueva FT propuesta mejora el sistema agregado antes de aprobarla? La parte fractal vive en frontera de investigación, no de producto.
El auto-evaluador y el overfitting.
El auto-optimizador de la fase 2 va generando código y reglas para destilar la capa determinista. Hay un riesgo real de overfitting al golden dataset: código que pasa los evals que existen y se rompe en cuanto aparece un caso ligeramente distinto. Hace falta una disciplina explícita de validación cruzada, generación adversarial de casos límite, y posiblemente un meta-evaluador que vigile que el código generado no esté memorizando el dataset en vez de generalizar.
Lo que sí está claro: si esto funciona, el código deja de ser el artefacto principal del negocio. Lo es la arquitectura de FTs, el golden dataset y la memoria del sistema que mantienen ambos vivos. El código aparece como subproducto de la calcificación, en sitios concretos donde merece la pena que aparezca.